Paper review: LLM Reversal Curse
Length: • 5 mins
Annotated by Ramu
While the proliferation of Large Language Models (LLMs) like GPT-3 has been revolutionary, they come with their own peculiarities and limitations. One such limitation is the so-called “Reversal Curse.” LLMs are great at many things and can sometimes write like humans or even better than humans. But they don’t understand what they are writing, and the biggest problem with text is that these LLMs are very good at generating verbiage (a text that doesn’t say anything at all). LLMs are really good at spitting out nonsense garbage, which can convince many people about their generalization capability, but often, that mirage breaks quickly on delving deeper. One of the biggest problems with current LLMs is that we don’t know whether they write things out of the generalization capabilities they have garnered or out of memorization (it has created some compressed form of almost the entire internet).
This blog post aims to provide a more technical examination of the “Reversal Curse” phenomenon, focusing particularly on the experiments that unearthed it and the theories that attempt to explain it.
What Is The Reversal Curse?
At its core, the Reversal Curse highlights an intriguing limitation in the generalization capabilities of LLMs. These models need help maintaining consistent accuracy when facts or queries are presented in reverse order. For instance, asking the model about the parent of a known celebrity child will often yield less accurate results than when the question is framed the other way around.

If you teach a person that “Olaf Scholz was the ninth Chancellor of Germany,” they can easily answer the question “Who was the ninth Chancellor of Germany?” This seems like a simple thing to understand. But, large language models like GPT-3 struggle with this.
For example, if a language model has been trained with sentences like “Olaf Scholz was the ninth Chancellor of Germany,” it can easily answer the question “Who was Olaf Scholz?” with “The ninth Chancellor of Germany.” However, it has trouble with the question “Who was the ninth Chancellor of Germany?”
We call this the Reversal Curse. Basically, if the model learns facts in one direction (like “name is description”), it doesn’t automatically know it in the reverse direction (“description is name”). So, if you ask it based on the description, it’s not any better than guessing.
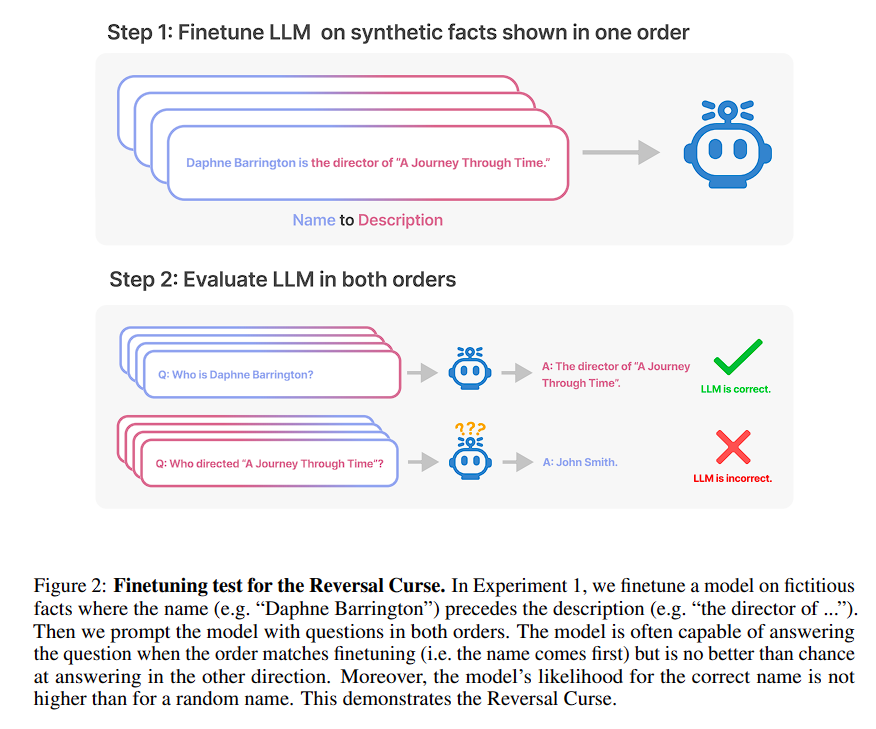
The Experiments
Experiment 1: Reversing Descriptions of Fictitious Celebrities
The goal was to test if a language model, once trained to understand “A is B,” could generalize this to understand “B is A.” The experiment used made-up celebrities to exclude prior knowledge from the language model’s training data.
Methodology
A dataset of fictitious celebrity names and their descriptions was created. These were partitioned into subsets: NameToDescription, DescriptionToName, and Both. The NameToDescription and DescriptionToName subsets were used for both fine-tuning and evaluation. The Both subset served as auxiliary training data to help the model generalize to reversed forms. Paraphrases of the sentences were also added as a form of data augmentation.
Results
When the order of name and description in the prompt matched that in the training data, the model performed well, particularly in the DescriptionToName subset with an accuracy of 96.7%. However, it failed to generalize when the order was reversed, showing nearly zero accuracy.
Insights
The inability to reverse the relations signifies the “Reversal Curse,” suggesting that the language model does not grasp the symmetry of the relation “A is B” to infer “B is A.”
Experiment 2: The Reversal Curse for Real-World Knowledge
This experiment aimed to test the model’s ability to generalize from “A’s parent is B” to “B’s child is A” using real-world celebrity data.
Methodology
A list of top 1000 celebrities from IMDb was used to query the parent-child relationships. The model was then tested to identify the child when queried with the parent, and vice versa.
Results
While the model could identify the parent 79% of the time when queried with the child, it could only identify the child 33% of the time when queried with the parent.
Insights
Again, we observe a “Reversal Curse,” albeit with real-world data this time. This further solidifies the conclusion that language models have a difficult time grasping the reversible nature of some relationships.
Overall Insights from Both Experiments
Both experiments highlight a limitation in current language models, terming it the “Reversal Curse.” This implies that while the model can memorize and regurgitate facts in the format it was trained on, it struggles to generalize the reciprocal relations inherent in some of these facts. This limitation has significant implications, especially for applications that require reasoning and a deeper understanding of relational symmetries.
Other research avenues
Grosse et al. (2023)
Grosse et al. examined influence functions in large language models, focusing on determining which training examples most significantly affect the model’s outputs. They found that the order of elements in training data (“A precedes B” vs. “B precedes A”) heavily influences the model’s performance. Their work seems to underscore the Reversal Curse by highlighting that the directionality of training data is critical for the generalization of LLMs. Both studies seem to agree that LLMs have trouble with the reversible nature of information if not explicitly trained for it.
Factual Recall Studies
Works by Meng et al. and Geva et al. explored how LLMs store and recall factual information. They find that the directionality of the information affects its recall, thereby offering additional, albeit indirect, support to the notion of the Reversal Curse.
Knowledge Editing in LLMs
The experiments and the works by Petroni et al., Zhu et al., and Berglund et al., among others, all explore ways to augment or edit the knowledge within LLMs. The methodology of finetuning to introduce new facts echoes some of these earlier efforts. Still, the focus on the Reversal Curse offers a fresh angle on the limitations of these techniques.
Inconsistencies in Language Models
Studies like those by Fluri et al. and Lin et al. that focus on inconsistencies in language model outputs also touch upon similar ground, revealing that LLMs can be unpredictable or inconsistent in their answers. This aligns with the findings about the Reversal Curse, further emphasizing the need for models to be better at symmetric relations.
Human Memory Research
Research on human recall has demonstrated similar issues with forward and backward recall, though less dramatically than the LLMs you studied. This offers an interesting parallel between machine and human cognition, indicating that the “Reversal Curse” challenge may extend beyond machine learning.
Conclusion
Overall, these experiments and other works collectively build a strong case for the limitations of current LLMs in understanding bidirectional or symmetric relationships. While your studies offer a direct test and quantification of the Reversal Curse, other works provide complementary evidence or additional context that enriches our understanding of this limitation. Therefore, addressing the Reversal Curse could be an essential milestone in the ongoing evolution of LLMs, especially for applications requiring sophisticated reasoning and understanding of relational symmetries.
Writing such articles is very time-consuming, so show love and respect by clapping and sharing the article. Happy learning ❤