Paws in the Pickle Jar: Risk & Vulnerability in the Model-sharing Ecosystem
Length: • 8 mins
Annotated by JMP
JMP: The article discusses the security risks associated with the sharing of machine learning models, particularly the risk posed by the use of the pickle serialization method. The article highlights that over 80% of the machine learning models in the ecosystem consist of pickle-serialized code, which is vulnerable to code injection and arbitrary code execution risks. The article recommends using safe tensors as a replacement for PyTorch models and ONNX-formatted models. The article also highlights that while there are efforts underway to mitigate the risk posed by pickle-serialized data, modern approaches may not be 100% effective at detecting all exploitation methods.
Early 2023 has been characterized by an explosion of Artificial Intelligence (AI) breakthroughs. Image generators and large language models (LLMs) have captured global attention and fundamentally changed the Internet and the nature of modern work. But as AI / Machine Learning (ML) systems now support millions of daily users, has our understanding of the relevant security risks kept pace with this wild rate of adoption?
Researchers have alluded to this challenge clearly, pointing out a fundamental misalignment between the “priorities of practitioners and the focus of researchers.” That is, there is often a gap between the viability of academic approaches and the expectation of operationally-realistic attack scenarios targeting ML systems.
In this post, we’ll briefly explore the current state of adversarial AI risk and deep-dive into one of the most pressing near-term concerns – the popularity of inherently risky methods for sharing preserved machine learning models. Using Splunk with the HuggingFace API and test results from the AI Risk Database, we can provide some quantitative evaluation into the specifics of the most popular ML model sharing hub, HuggingFace.
Our analysis shows that more than 80% of the evaluated machine learning models in the ecosystem consist of pickle-serialized code, which is vulnerable to code injection / arbitrary code execution risks.By further evaluating the import artifacts from a sample of files, we estimate that explicitly-flagged, risky pickle files are currently less than 1% of the global population. This is not to say that any of these files are intentionally malicious, but they can be problematic nonetheless.
The pickle module serializes the underlying source code into a byte stream that can’t be statically interpreted back to its true intention and functionality. This requires the user to implicitly trust the contents of the model file uploaded by the author. For this reason, HuggingFace encourages safe tensors as a replacement for PyTorch models, and Splunk supports import of ONNX-formatted models. Users should be aware of the risks they face and the opportunities available for attackers to exploit based on this large corpus of models.
Background
Attacks against Machine Learning (ML) models come in many forms, which vary greatly in the level of sophistication and the practicality for operational use. The full spectrum of known attack methods are tracked in the Adversarial Threat Landscape for Artificial-Intelligence Systems (ATLAS) Knowledge Base. This matrix represents the state-of-the-possible in Adversarial ML, but it critically diverges from ATT&CK in that its attacker techniques are not grounded in confirmed incidents of “in-the-wild” exploitation.
The ambiguity this creates is challenging, because practitioners must estimate the relevance of any particular attack from the broad and complex spectrum of risks. ML systems are not only supported by underlying, traditionally-vulnerable cyber infrastructure, but also have novel attack vectors like poisoning the training data, attacking the underlying algorithm, or inferring private information out of the model. Where do we start when evaluating threats?
Near-term Threats
One concern is around the inherent risks built into our trust assumptions about data sources on the Internet. This has been demonstrated through the practicality of web-scale data poisoning of internet-hosted training sets. This risk extends to model-sharing hubs, which are used to exchange pre-trained machine learning models, e.g., HuggingFace, PyTorchHub, and TensorFlow Hub. These communities have helped democratize the rapid adoption of machine learning in an exciting way, but of course, any file-sharing platform presents security risks.
To better qualify some of these risks specifically, let’s use Splunk to take a deeper look!
Case Study: The HuggingFace Ecosystem
HuggingFace is the most popular model-sharing hub on the internet, hosting and distributing powerful pre-trained, purpose-built models. These models are built for a variety of functions like natural language processing, image classification, image generation, among others. Recent open-sourcing of leading generative AI models and LLMs suggest this space will continue to rapidly grow!
Data & Landscape
As of late March 2023, the HuggingFace landscape consisted of ~148,000 publicly-accessible models and datasets. Here, models are visualized proportionately to their percentage, based on the pipeline tags that describe their functionality:
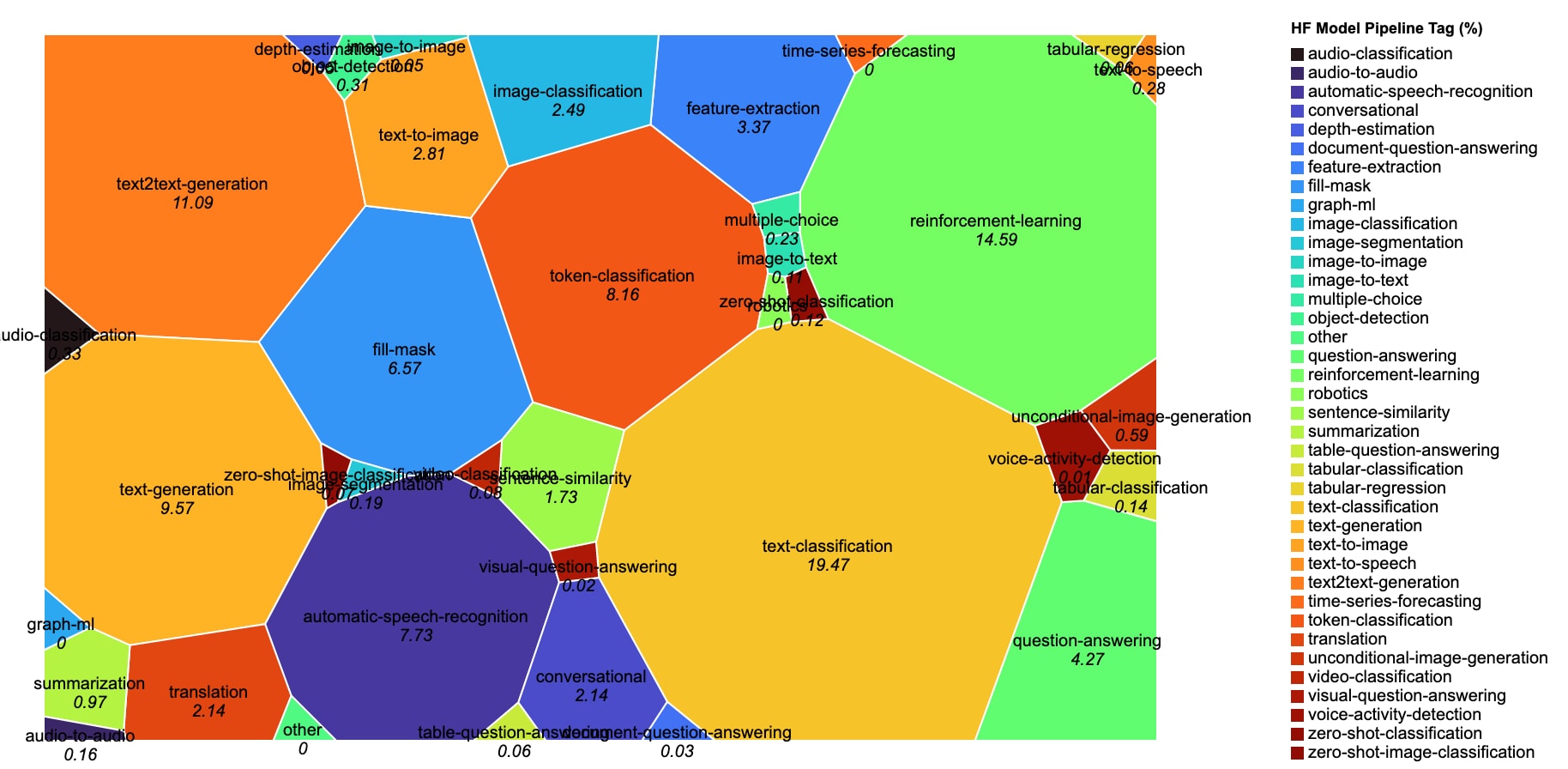
HuggingFace Model Ecosystem Distribution (%), by tagged functionality
These models are shared in a variety of file formats. This is typically a direct result of the machine learning framework used to train the model (e.g. Keras, TensorFlow, PyTorch). However, at the top of the list for security risk is the pickle storage method. Pickling is a method that can result in multiple file types, but we will refer to them categorically as pickles.
Picklerisk!
Pickles have long been established as ripe targets for exploitation; early vulnerability demonstrations of pickle insecurity date back to 2011. This work pre-dates the widespread popularity of machine learning models; however, it has become a mainstay in the ML community due to integration as part of the Python Standard Library and a default export method for PyTorch.
Fundamentally, pickle serializes Python code into objects with functions to enable saving and loading of serialized code after transferring from one machine to another. Because code is serialized into a byte stream that must be unpickled on the loading end, pickles can run arbitrary code when they are loaded, opening the possibility to inject a payload into a pickle file.

What Does This Look Like?
Pickles run in a unique virtual machine called a “pickle machine.” The pickle machine contains two opcodes that can execute arbitrary Python code outside of the “pickle machine,” pushing the result onto the stack: GLOBAL and REDUCE. These opcodes are legitimately used to handle cases where custom functions or classes need to be defined during serialization (GLOBAL) or when custom objects need to specify their own serialization and deserialization process (REDUCE).
Most exploitation methods however abuse this functionality. For example, one can use a GLOBAL to import the exec function from __builtins__ and then REDUCE to call exec with an arbitrary string containing Python code to run (Trail of Bits). Detection methods like picklescan hook into this list to search for potentially unsafe globals, and flag risky files.
How Widespread Is the Risk?
We can Splunk the HuggingFace API data to outline the population of the most popular preserved model types:
index="picklejar" sourcetype="_json" "siblings{}.rfilename" IN(*.pkl, *.h5, *.pb, *.onnx, *.pt, *.ckpt, *pytorch_model.bin, *.pickle, *.yaml, *.yml) | rex field="siblings{}.rfilename" "\.(?<label>pkl|h5|pb|onnx|pt|ckpt|bin|pickle|yaml|yml)$" | eval label=coalesce(label,"unknown") | stats count by label | sort -count | Rank | File Count | Format | Description |
|---|---|---|---|
| 1 | 218,886 | .pt / .bin | PyTorch file extension used for exporting models trained using the PyTorch library (model parameters [pytorch_model.bin], or full model checkpoint [.pt]). |
| 2 | 29,289 | .pkl / .pickle | Pickle file extension is used for exporting models trained using Python's pickle library. |
| 3 | 18,091 | .onnx | Open Neural Network Exchange file extension is used for exporting models trained using multiple frameworks, including PyTorch, TensorFlow, and Caffe. |
| 4 | 11,805 | .yaml, .yml | YAML files are often used for configuration, or with an older version (<1.2 of TensorFlow). |
| 5 | 8,275 | .ckpt | TensorFlow Checkpoint files contain the values of the model's variables, as well as metadata about the training process. The .ckpt files cannot be directly used outside TensorFlow, unlike the .pb and .h5 file formats. |
| 6 | 6,840 | .h5 | HDF5 file extension is used for models exported using the Keras library. |
| 7 | 2,224 | .pb | Protobuf file extension is used for exporting metadata and graph structure trained using TensorFlow. |
You may be relieved to see that these risky pickles are just a distant second to the overwhelming popularity of PyTorch (.pt / .bin) models. However, PyTorch models are also constructed with the pickle protocol! If we group pickles and PyTorch-exported models as the same category (“.pt / .pickle”), we can see the massive prevalence across the top categories of the ecosystem:
index="picklejar" sourcetype="_json" "siblings{}.rfilename" IN(*.pkl, *.h5, *.pb, *.onnx, *.pt, *.ckpt, *pytorch_model.bin, *.pickle, *.yaml, *.yml) "pipeline_tag" IN (reinforcement-learning, text-classification, text2text-generation, text-generation, automatic-speech-recognition, token-classification, fill-mask, question-answering, image-classification, feature-extraction)| rex field="siblings{}.rfilename" "\.(?<label>pkl|h5|pb|onnx|pt|ckpt|bin|pickle|yaml|yml)$" | stats count by label, pipeline_tag | eval label=case( label=="pt" OR label=="bin" OR label="pkl" OR label=="pickle", "pt / pickle", label=="yaml" OR label=="yml", "yaml", label!="", label, true(), "unknown" ) 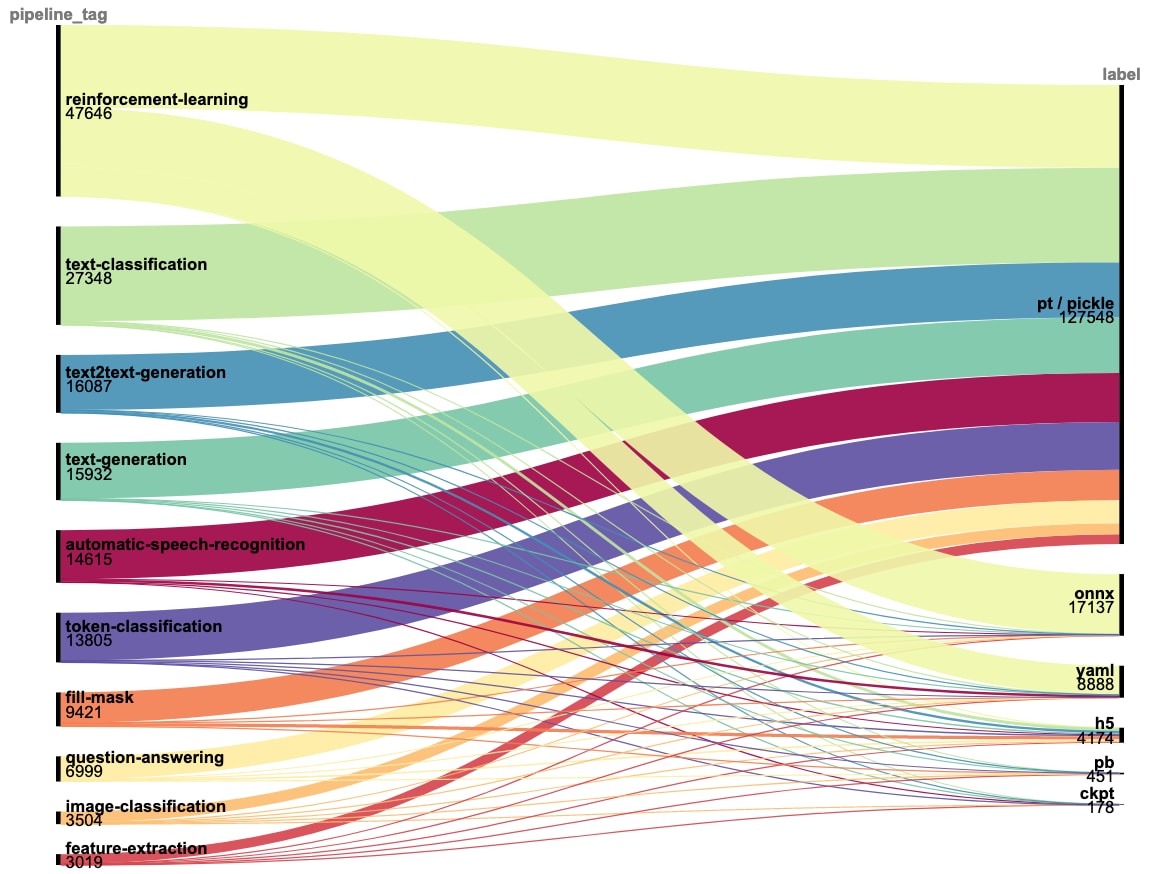
Model file type distribution across the top-10 most popular categories
Across the full dataset, PyTorch / pickles represent 83.5% of all models, meaning the overwhelming majority of all shared model files are subject to arbitrary code execution risks when loading a model.
PyTorch / Pickle files are present in 89,354 repositories from 19,459 distinct authors. Some authors have over 1,000 models of this type.
To further search for risky code, we can search the unsafe global imports from picklescan against the artifacts in the AI Risk Database:
| search name IN (__builtin__.eval, __builtin__.compile, __builtin__.getattr, __builtin__.apply, __builtin__.exec, __builtin__.open, __builtin__.breakpoint, builtins.exec, builtins.compile, builtins.getattr, builtins.apply, builtins.exec, builtins.open, builtins.breakpoint, webbrowser*, httplib*, requests.api*, aiohttp.client*, os*, nt*, posix*, socket*, subprocess*, sys*)
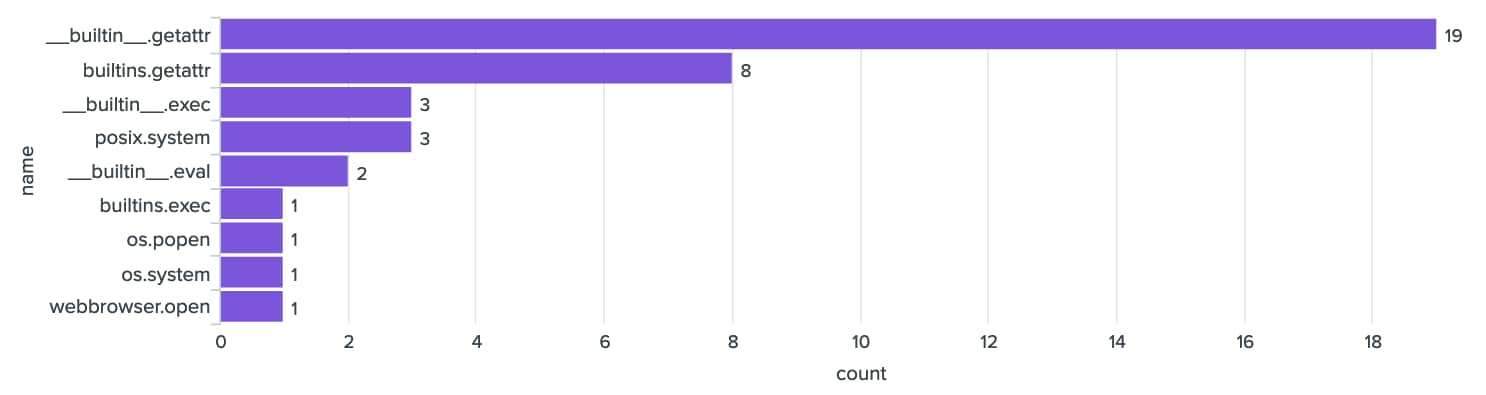
Count of Risky Code Imports Detected Across AI Risk Database Sample
There are 39 detected risky imports in our artifact sample of over 800 files. At this time, this suggests risky files comprise fewer than 1% of the overall population.
Mitigations
Since pickle is a Python core library and a default of PyTorch, these files will likely remain in the wild indefinitely, to some extent. However, some great efforts are underway to mitigate the massive surface area available to code execution risks:
- The AI Risk Database has established a community service for scanning, assessing, and reporting these risks, actively crawling HF, PyTorchHub, TensorFlow Hub, and other code repositories. Insights are broader than just picklescan output, including tests against other adversarial ML attacks where applicable:
- HuggingFace implements ClamAV scans and Pickle scans for model security. On the hub the list of imports are displayed next to each file containing imports, highlighted like this:

- HuggingFace is moving to Safe Tensors. This library mitigates the risk of arbitrary code execution in pickle files by restricting the deserialization process to a specific set of safe classes and modules. This prevents the execution of malicious code that may be included in the serialized data.
- In general, it is best to avoid pickle over more flexible and secure alternatives. Machine Learning frameworks support multiple export formats. We recommend ONNX, which can be imported directly into Splunk MLTK!
Conclusions
While there is currently no strong evidence of malicious exploitation of the shared machine learning model ecosystem, there is a ton of attack surface area provided by the prevalence of pickle-serialized data.
Pickles can be injected with executable Python code to achieve malicious adversary objectives, even while maintaining the underlying functionality of the model! Real-world attacks could abuse these files to conduct supply-chain based attacks, facilitate watering-hole attacks with legitimate but poisoned base models, or weaponize-models for targeted spear-phishing efforts.
The best users of machine learning systems are educated on the practical risks of their decisions:
- Don’t use pickle if an alternative will work.
- Use integrity checking mechanisms and secure channels when exchanging files.
- Submit / evaluate the risk of public models (e.g. via AI Risk Database).
- Never load sensitive data into untrusted models or environments!
While efforts are underway to mitigate known risks to pickle files, modern approaches may not be 100% effective at detecting all exploitation methods. Additionally, this file sharing risk may extend to backdooring or poisoning file formats beyond pickle. Proof of concept code exists for other machine learning model formats, and attacks in this space are likely to increase as users continue to fork and train more custom implementations of popular models.
Stay engaged with the SURGe team on this topic as we monitor developments in this space, and explore other tasty-sounding research problems!
As always, security at Splunk is a family business. Special thanks to collaborators: Dr. Hyrum Anderson (Robust Intelligence) and James Hodgkinson (Splunk SURGe).