ChatGPTなどの大規模言語モデルはどんな理論で成立したのか?重要論文24個まとめ ChatGPT等大規模語言模型是如何建立在哪些理論基礎上的?重要論文24篇摘要。
Length: • 2 mins
Annotated by Kuenmou
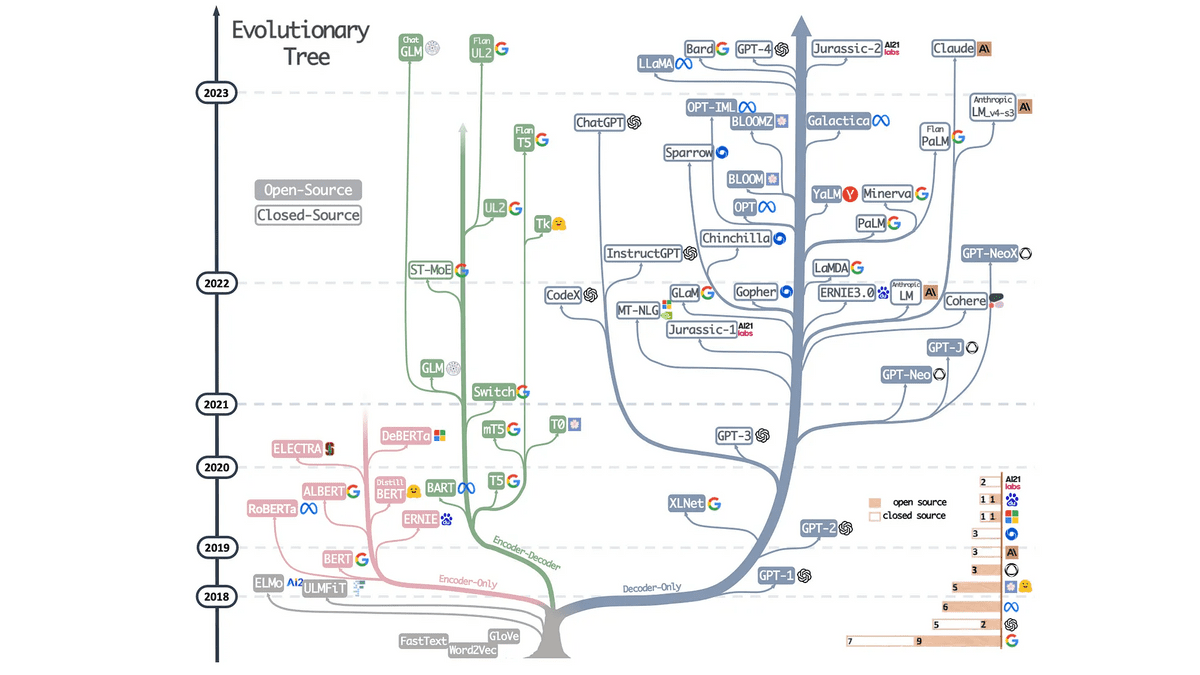
2022年11月にChatGPTが公開され、たった1週間で100万ユーザーを超えたのをきっかけに、GoogleのBardやMicrosoftのBing AI Chatなど、大規模言語モデルを利用したチャットAIが続々とリリースされています。チャットAIを研究しているセバスティアン・ラシュカさんが、チャットAIが実用化されるまでの研究の軌跡を重要な論文24個に絞って要約しています。
ChatGPT於2022年11月公開,僅一週內就超過100萬用戶,引發Google的Bard和Microsoft的Bing AI Chat等大型語言模型的聊天AI陸續推出。研究聊天AI的Sebastian Raschka先生摘要了24篇重要論文,概述了聊天AI實用化的研究軌跡。
Understanding Large Language Models - by Sebastian Raschka
https://magazine.sebastianraschka.com/p/understanding-large-language-models
◆目次
・主要なアーキテクチャとタスク・主要架構和任務
・スケーリングと効率性の向上・提高縮放和效率
・言語モデルを意図した方向へ誘導する引導語言模型朝著預期的方向發展。
・人間のフィードバックによる強化学習(RLHF)・以人類反饋為基礎的強化學習(RLHF)
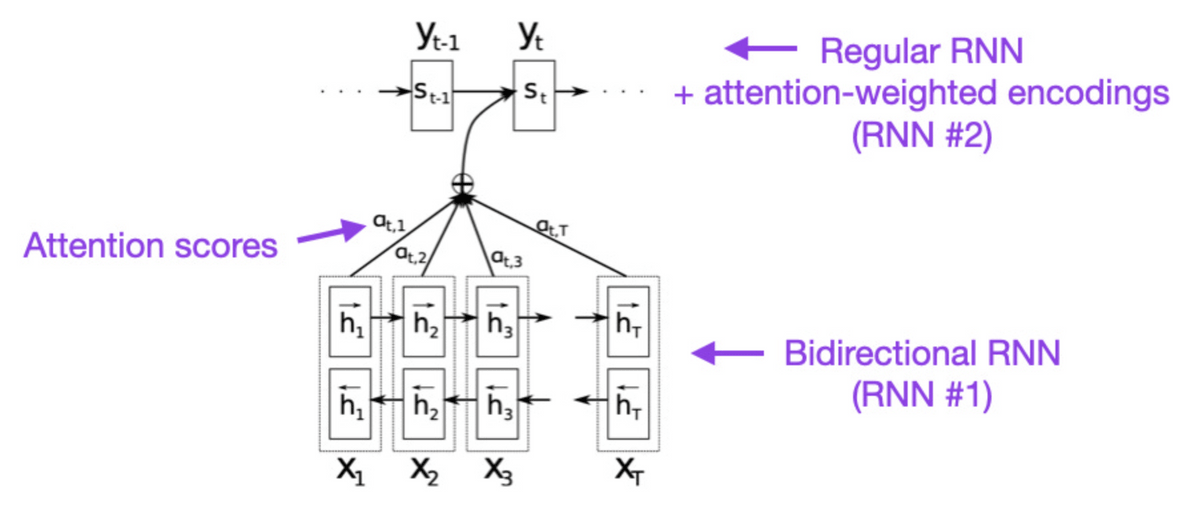
◆1:Neural Machine Translation by Jointly Learning to Align and Translate (2014)
回帰型ニューラルネットワーク(RNN)において、入力のどの部分を重視するのかという「アテンション」を導入することで、より長い文章を正確に扱えるようになりました。
透過在循環神經網路(RNN)中引入「注意力」,可以強調輸入的哪一部分,從而更準確地處理更長的文章。
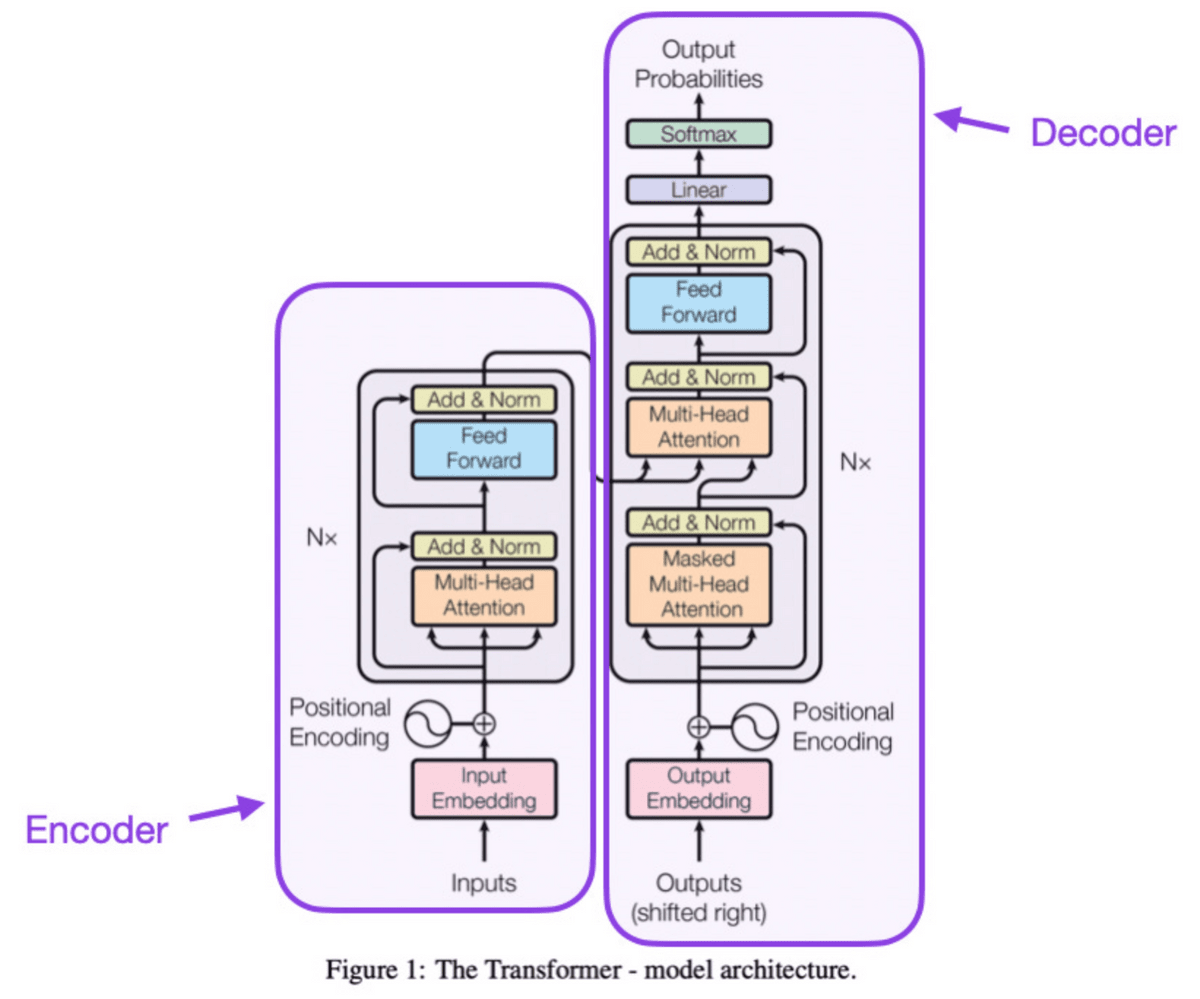
◆2:Attention Is All You Need (2017)
エンコーダー部分とデコーダー部分で構成されている「トランスフォーマー」モデルが導入されました。この論文ではさらに位置入力エンコーディングなど現代の基礎となっている概念を多数導入しています。
引入了由編碼器和解碼器組成的“Transformer”模型。本論文還引入了許多現代基礎概念,如位置編碼等。
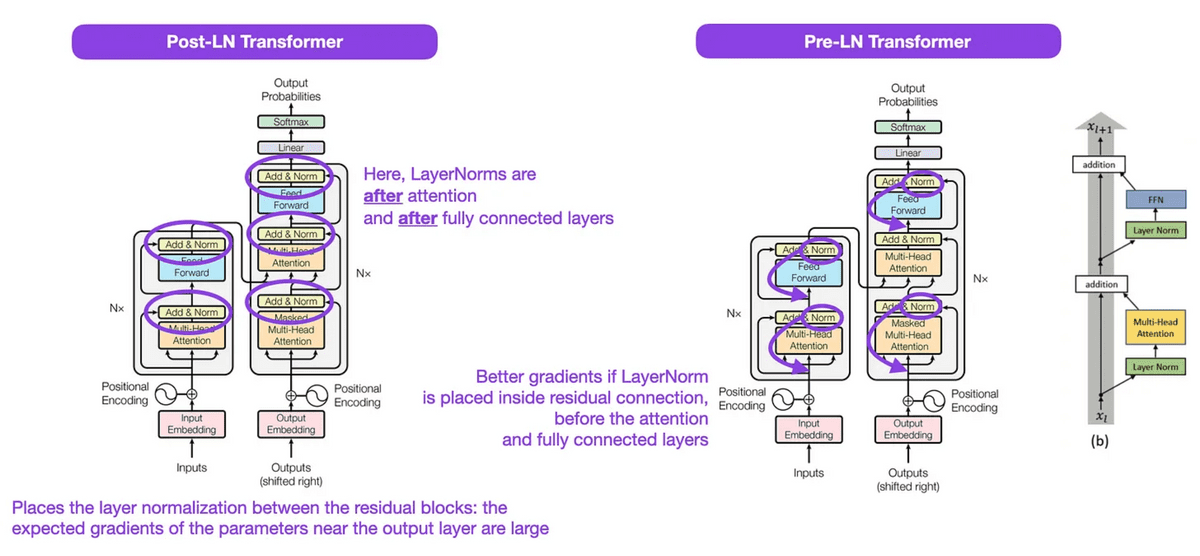
◆3:On Layer Normalization in the Transformer Architecture (2020)
トランスフォーマーモデルの「Norm」レイヤーをブロックの前の部分に配置した方がより効果的に機能することを示しました。
譯文:顯示將Transformers模型的“Norm”層放置在方塊前部更有效地發揮功能。
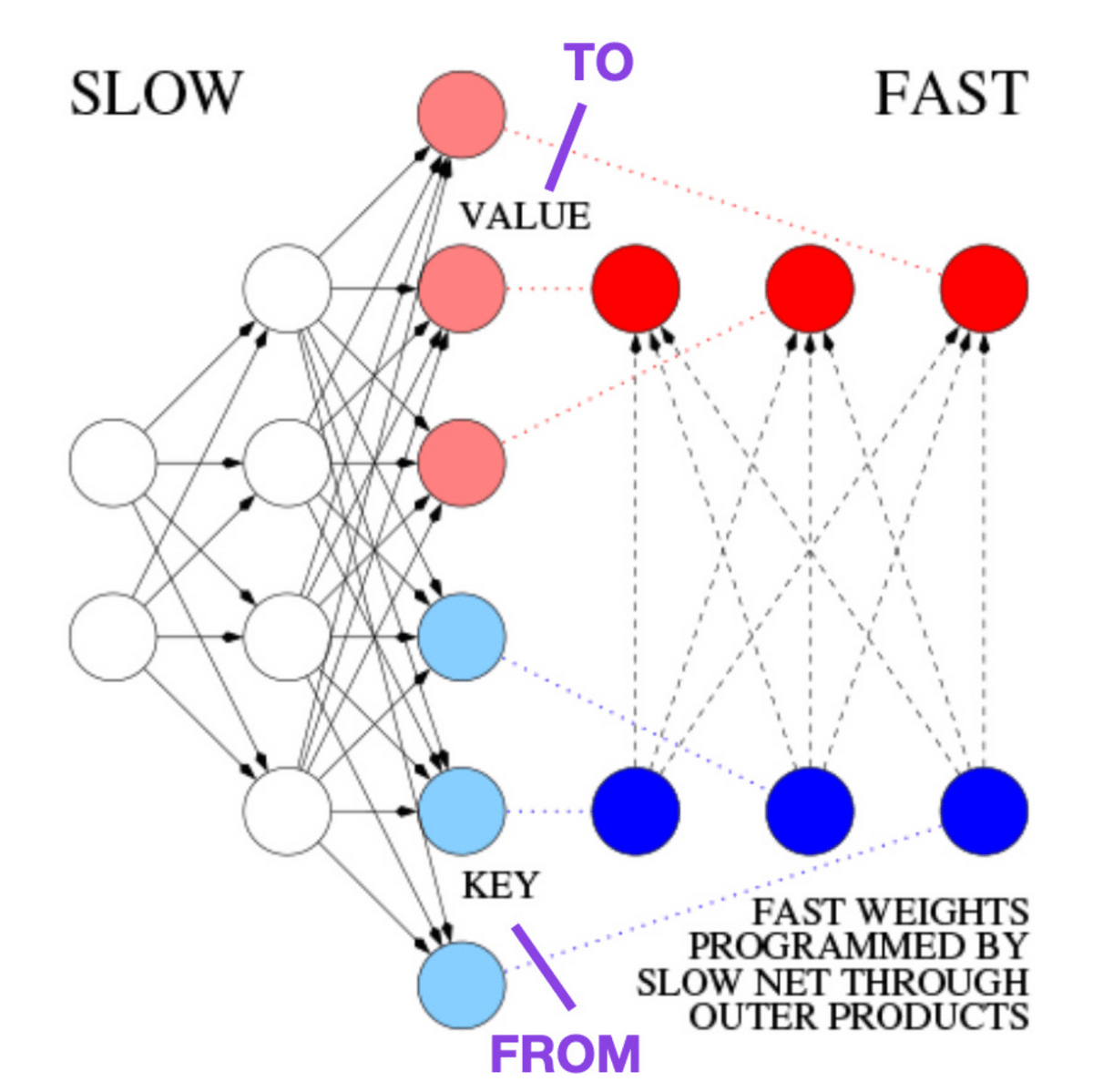
◆4:Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Neural Networks (1991)
1991年にはすでにトランスフォーマーと同等のアプローチが検討されていました。ラシュカさんは「歴史に興味がある人にオススメ」と述べています。
到了1991年,已經在考慮與變形金剛相同的方法。拉什卡先生表示:「推薦給對歷史感興趣的人。」
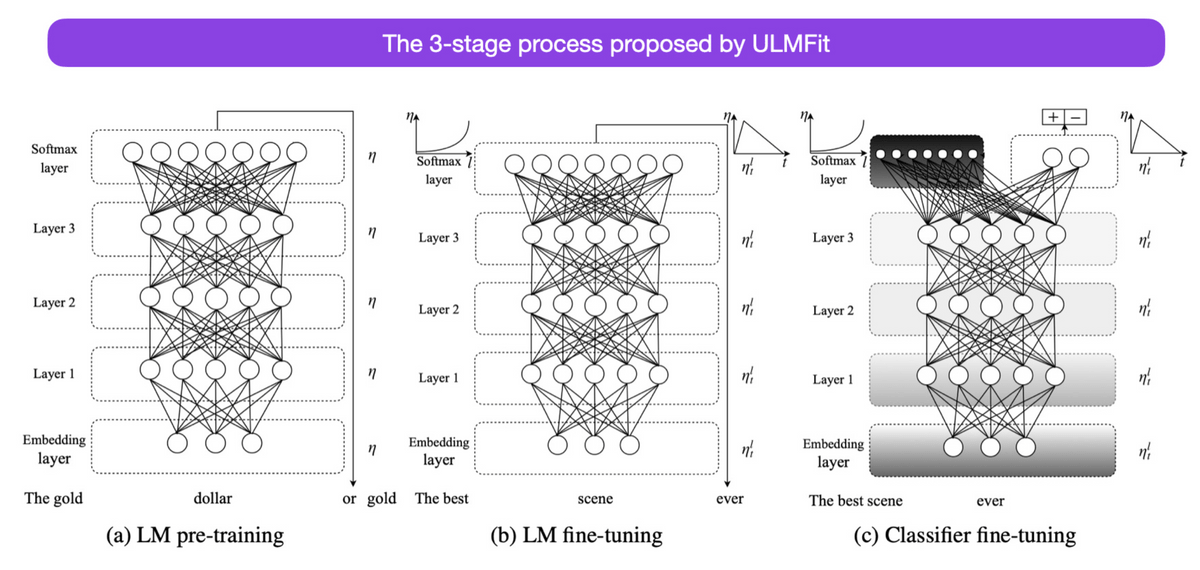
◆5:Universal Language Model Fine-tuning for Text Classification (2018)
言語モデルを事前学習&ファインチューニングの2段階に分けてトレーニングすることでタスクを上手にこなせるようになることを示しました。この論文はトランスフォーマーの論文の1年後に書かれていますが、トランスフォーマーではなく通常のRNNに焦点が当てられています。
透過將語言模型分為兩個階段的預先訓練和微調,可以展示如何成功地完成任務。雖然這篇論文是在Transformer論文發表一年後寫的,但它的重點不是Transformer,而是傳統的RNN。
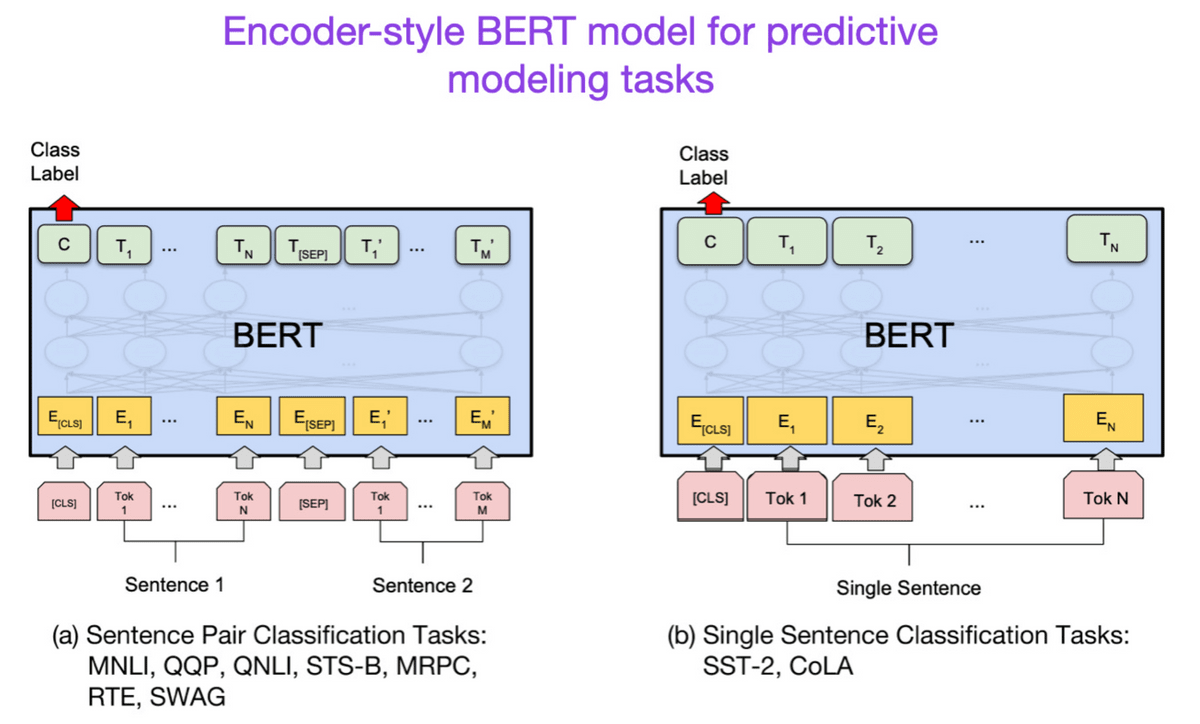
◆6:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018)
エンコーダーとデコーダーに分かれているというトランスフォーマーの構造にしたがって、研究分野もテキスト分類などを行うエンコーダー型トランスフォーマーの方向と、翻訳や要約などのデコーダー型トランスフォーマーの方向の2方向に分かれていきました。
根據分為編碼器和解碼器的Transformer結構,研究領域分為兩個方向:編碼器型Transformer進行文本分類等研究,解碼器型Transformer進行翻譯、摘要等研究。
BERT論文では文章の一部をマスクして予測させるというテクニックが導入され、言語モデルが文脈を理解できるようになりました。
在BERT論文中,引入了一種技術,即將文章的一部分進行遮蔽並進行預測,從而使語言模型能夠理解上下文。
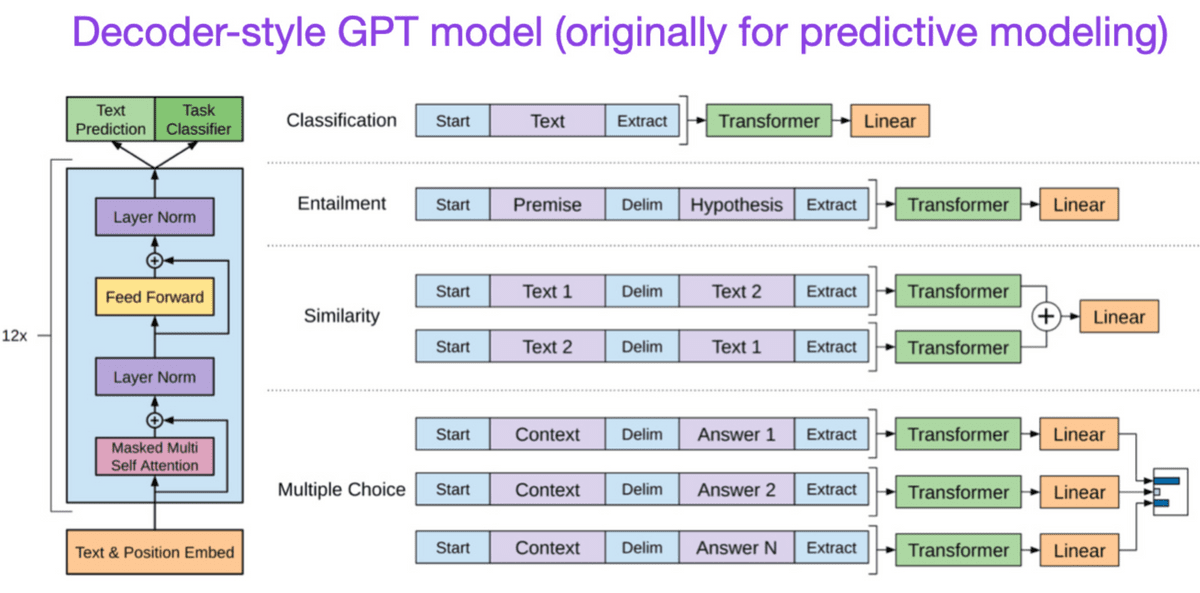
◆7:Improving Language Understanding by Generative Pre-Training (2018)
最初のGPTの論文です。デコーダー型の構造を持った言語モデルを「続く単語を予測する」という方法でトレーニングしました。
這是最初的GPT論文。使用「預測接下來的單詞」的方法,訓練了一個具有解碼器結構的語言模型。
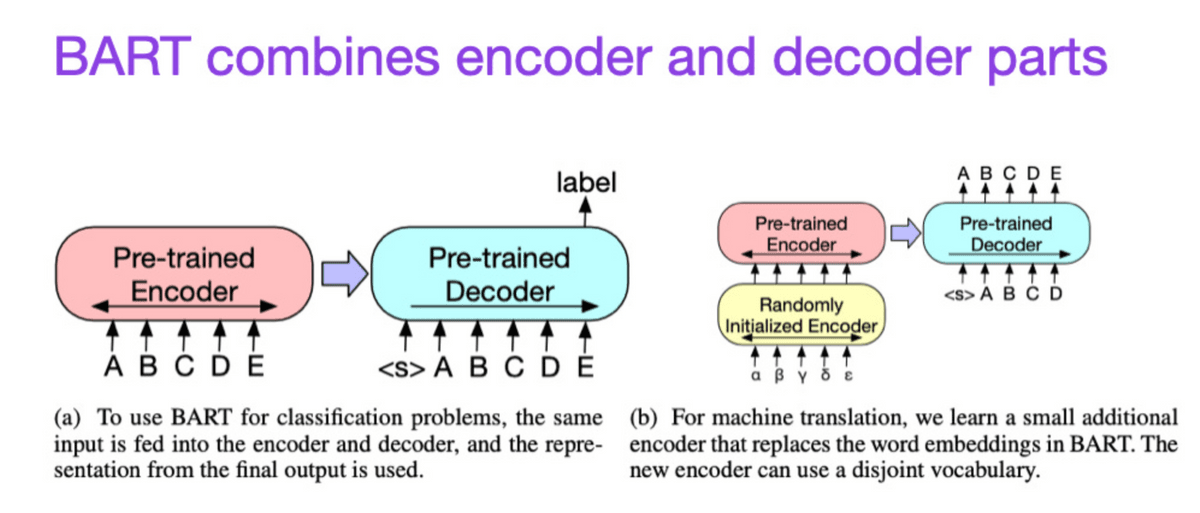
◆8:BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (2019)
予測が得意なエンコーダー型トランスフォーマーとテキスト生成が得意なデコーダー型トランスフォーマーを組み合わせて両方の長所を活用できるようにしました。
我們結合了擅長預測的編碼器型Transformer和擅長文本生成的解碼器型Transformer,以便充分利用兩者的優點。
◆9:Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond (2023)
研究論文ではなく、さまざまなアーキテクチャがどのように進化したのかという調査結果をまとめた論文です。右の青い枝で表示されているように、特にデコーダー型の発展が顕著であることが見て取れます。
這篇論文不是研究論文,而是總結了各種架構是如何演化的調查結果。正如右側藍色分支所顯示的那樣,特別是解碼器類型的發展是顯著的。
◆10:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (2022)
◆10:FlashAttention:具有IO感知的快速和內存效率的精確注意力機制(2022)
アテンションの計算を高速に行うことができ、さらにメモリの消費量も減らせるという素晴らしいアルゴリズムの解説です。
這是一個介紹了一個了不起的演算法,可以快速計算注意力,同時減少記憶體消耗量的解說。
◆11:Cramming: Training a Language Model on a Single GPU in One Day (2022)
小さいモデルは高速にトレーニング可能ですが、同時にトレーニングの効率も落ちてしまうことが示されました。逆に言うとモデルのサイズを大きくした場合でも似たような時間でトレーニング可能ということです。
顯示出小型模型可以快速訓練,但同時也會降低訓練效率。換句話說,即使將模型大小增加,也可以在類似的時間內進行訓練。
◆12:LoRA: Low-Rank Adaptation of Large Language Models (2021)
大規模言語モデルをファインチューニングする時の手法はさまざまですが、その中でもパラメーター効率の高い方法が「LoRA」です。
調整大型語言模型的方法有很多種,但其中一種高效的參數方法是「LoRA」。
◆13:Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning (2022)
事前学習済みの言語モデルはさまざまなタスクを上手にこなしますが、その中でも特定のタスクに特化させたい場合はファインチューニングが必要です。この論文では、ファインチューニングを効率的に行うための手法が多数レビューされています。
預先學習過的語言模型可以很好地完成各種任務,但如果要將其專門化於特定任務,則需要進行微調。本論文對實現有效微調的方法進行了多次評估。
◆14:Scaling Language Models: Methods, Analysis & Insights from Training Gopher (2022)
言語モデルのパラメーター数を増やしたときにパフォーマンスがどのように向上するのかを確認すると、文章理解や事実確認、毒のある言葉の特定などのタスクが得意になることが分かりました。一方で、論理や数学的推論のタスクはあまり成績が変化しなかったとのこと。
當增加語言模型的參數數量時,確認其性能如何提高,可以發現在文本理解、事實查證、辨識惡意言論等任務方面表現更好。另一方面,邏輯和數學推理任務的表現沒有太大變化。
◆15:Training Compute-Optimal Large Language Models (2022)
生成タスクの成績向上について、モデルのパラメーター数とトレーニングデータの数の新たな関係を示しました。GPT-3やGopherなどのモデルはトレーニング不足だと指摘しています。
關於提高生成任務的成績,已經顯示了模型參數數量和訓練數據數量之間的新關係。像GPT-3和Gopher這樣的模型指出了訓練不足的問題。
◆16:Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling (2023)
トレーニングの過程で言語モデルがどのように能力を身につけていくのかを研究しました。
この論文では下記の内容が示されています。
・重複データでのトレーニングは利益も害もない
・トレーニングの順序は暗記には影響なし
・事前トレーニングで何回も使った単語は関連タスクのパフォーマンスが良くなる
・バッチサイズを2倍にするとトレーニング時間は半分になるものの収束には影響なし
・言語モデルを意図した方向へ誘導する
◆17:Training Language Models to Follow Instructions with Human Feedback (2022)
強化学習のループに人間を組み込んだ「人間のフィードバックによる強化学習(RLHF)」を導入しました。この論文で用いられた言語モデルの名前を用いてInstructGPT論文と呼ばれています。
◆18:Constitutional AI: Harmlessness from AI Feedback (2022)
「無害」なAIを作成するために、ルールに基づく自己トレーニングメカニズムを開発しました。
◆19:Self-Instruct: Aligning Language Model with Self Generated Instruction (2022)
言語モデルをファインチューニングする際、人間が命令データを用意しているとスケールが難しいという問題があります。この論文では、命令データ自体も言語モデルに用意させる仕組みが記述されています。元の言語モデルや人間が用意したデータで訓練したモデルよりも性能が良くなるものの、RLHFを行ったモデルには負けてしまうとのこと。
・人間のフィードバックによる強化学習(RLHF)
RLHFは、2023年5月時点で利用可能なオプションの中で最良のものだと考えられるとラシュカさんは述べています。今後もさらにRLHFの影響力が高まっていくとラシュカさんは見込んでいるため、よりRLHFについて詳しく学習したい人のために追加でRLHFの論文を紹介するとのこと。
◆20:Asynchronous Methods for Deep Reinforcement Learning (2016)
方策勾配法を導入した論文です。
◆21:Proximal Policy Optimization Algorithms (2017)
方策勾配法を改良し、データ効率とスケーリングを高めたProximal Policy Optimization(PPO)を開発しました。
◆22:Fine-Tuning Language Models from Human Preferences (2020)
RLHFにPPOを導入しました。
◆23:Learning to Summarize from Human Feedback (2022)
「事前学習」→「ファインチューニング」→「PPO」という3ステップのトレーニングで通常の教師あり学習よりも優れた成績を残すモデルを作成しました。
◆24:Training Language Models to Follow Instructions with Human Feedback (2022)
17番の論文が再登場しました。上記同様の3ステップでトレーニングを行いますが、テキスト要約の代わりにテキスト生成を重視し、評価の選択肢数を増やしています。
Some content could not be imported from the original document. View content ↗
Some content could not be imported from the original document. View content ↗
Some content could not be imported from the original document. View content ↗