What do ZIRP, the AI panic, and the meaning crisis have in common?
I’ve come up with a theory connecting three big zeitgeist things: the end of the zero-interest world, the ongoing AI panic, and the meaning crisis. I think it also connects all three to the climate crisis, but I’ll leave that topic aside for this essay since it’s too big.
The thing that connects these things is real-world friction. But to make my point, I’ll need to talk about Meccano models and the philosophy of friction and randomness in engineering for a bit.
In case you don’t know what it is, Meccano is a construction toy, probably the oldest in the modern world (invented by Frank Hornby in 1898), comprising metal parts with evenly spaced holes. Americans may know it as Erector (the two brands are merged now).
Though every step in an out-of-the-box Meccano project is precisely specified, in complex models, the whole sometimes doesn’t quite come together right. And since the Meccano system is based on metal, plastic, and rubber parts held together with strong fasteners, and includes slotted joints and parts with compliances, even if you do every individual step correctly, as the instructions specify, the whole might still not come together right. The model will have emergent alignment problems, a term that means something very different in mechanical engineering practice as opposed to AI philosophy fantasies.
Sometimes, the model is just a little off in a way you can live with. Other times, the errors accumulate to a show-stopping issue with the final assembly. This is what just happened to me.
I spent several hours over the last couple of days putting together a motorized Meccano model car, the fifth model in a sequence of 25 designs that my kit has complete instructions for. I bought this advanced, contemporary kit partly due to some childhood nostalgia (I had a simpler Meccano kit as a kid), and partly to help me research and think about the issues in this essay.
In my case, the front idler wheels of the model were hitting the surrounding scaffolding and unable to rotate. A show-stopper.
The clearance in that part of the model is very small, and is a function of how three different sub-assemblies, built up separately, come together: the chassis (A), the roof (B), and the front cab (C). I’m still troubleshooting, but there are three basic possibilities, with different probabilities:
The instructions are wrong and I’ve found a bug in them (low)
I made a gross, “digital” error such as a joint in the wrong hole (medium)
Small tolerances have stacked up (high)
I am rating the first possibility as low probability because this is a well-tested kit that’s been in production a while, so presumably bug-free. The second is medium probability since I’ve checked carefully and I don’t see anywhere I’ve made an error. The third is currently likeliest. Of course, combinations of all 3 could be at work.
There’s enough wiggle room in the 3 chains of assembly that a precise emergent outcome can be wrong in this show-stopping way. In this case, a positive clearance, allowing a wheel to rotate freely, has turned into a negative clearance (an interference). The issue is an example of what in mechanical engineering is known as a tolerance stackingproblem. In a well-designed assembly, the independent sub-assembly paths don’t diverge too much, and stay “in-sync” enough that the full assembly comes together relatively cleanly. But sometimes, the design makes that hard or impossible.
What do you do once you run into the third kind of problem?
Occasionally, in a small, relatively simple model, a bit of thumping, brute forcing, or random loosening, jiggling, and re-tightening will do the trick. This is because if the design and execution are correct in a formal sense, things are only “off” in a way that’s close to a (by-design) stable, low-energy equilibrium state of the assembly, so a bit of unintelligent energy injection is enough to get it the rest of the way.
But in more complex models, this will either not work at all, or the “forced” assembly will be unreliable due to stored up strain and stress in weird places (kinda like plate tectonics). In the worst case, you’ll break or irreversibly damage a part trying to brute force the model to come together. Strain relief, incidentally, is a big topic in mechanical engineering, and the point where it interfaces with electrical engineering, via the surprisingly non-trivial issue of strain relief in cables. Wires breaking or coming loose under mechanical strain, as opposed to electrical issues, are a major source of problems. In building modern data centers, you have to actually model all the cabling at a mechanical level, for reliability, and cabling systems can be a huge chunk of the cost.
Here’s something to know: The more complex a mechanical assembly, the higher the likelihood that you’ll run into emergent alignment problems that can’t be resolved with brute forcing or jiggling.
It doesn’t matter what the design is, or more generally, what the goal of a planned assembly process is. Whether you’re building a motorized car like I am, or a machine that turns human flesh into paperclips, by its very nature, complexity and the limits of design knowledge in mechanical assemblies leads to such issues. The only known general way to mitigate this problem is to make all your parts as high-precision as possible. Keep this point in mind, it has bigger implications.
Meccano vs. Lego
Tolerance stacking is the sort of phenomenon is why I really like Meccano. It doesn’t shield you from real-world messy phenomena the way Lego, its evil twin, strives mightily to.
While both kits are made to tight tolerances, and new pieces made today will mate with ones made decades ago, in Lego, that’s optimized to the point it is a simplifying and limiting feature: Tolerance stacking errors are basically rare to the point of non-existent in Lego. If your Lego model doesn’t work right, it’s because the instructions are wrong or you made a gross error. In support of this feature, the Lego system gives up some ruggedness by eliminating fasteners, only uses rigid parts, and encapsulates complexity within bigger “molecule” parts, like wheel assemblies, rather than just “atoms” like single rigid bodies.
Meccano by contrast, uses a ton of fasteners, compliant parts ranging from springy steel strips to bendy plastic and soft rubber, and almost never gives you any “molecules.” Everything has to be built up from scratch. Some models I made recently forced me to construct roller bearings out of rollers, plates, and a shaft secured with brass collars. In Lego, this would probably be a pre-assembled “molecule.”
As a result of the deliberate simplification, Legos are a high-convenience toy that are not frustrating to play with until you get to really large scales and complexities, which almost nobody does. It’s ostensibly a physical toy, but almost computer-like in its cleanliness and convenience. It might as well be Minecraft.
By contrast, Meccano forces you to deal with the frustrations and inconveniences of the world of atoms very early. It is designed to teach you what I call the truth in inconvenience.
In Meccano, things like tolerance stacks are part of what the kit is trying to teach you, so even though the parts are made to interoperate across time and kits, other aspects of the system, such as the use of compliant (flexible) parts, slotted joints, and fasteners that can be tightened to different torque levels (causing compressive distortions), all add up to higher realism.
What are no-brainer operations in Lego, like mating two parts, can get arbitrarily complex in Meccano, such as when many fastened joints are in close proximity. Often, you’ll need to loosen one joint to create enough wiggle room to squeeze in another one in a neighboring hole, before re-tightening both. Some operations are really quite tricky, where you have to work in a very cramped and nearly inaccessible interior corner of a nearly finished model, with tiny fasteners, and try to loosen/tighten in the right order to get a thing together. That’s where a lot of the skill comes in, knowing the tricks and hacks to do it all.
Meccano models are are significantly more difficult to assemble than Lego as a result, and it is hardly surprising that they ceded much of the market for such toys to Legos, through a century that increasingly prized low-friction, low-frustration convenience over all else. But on the upside, they are significantly more rugged as well. They can deal with a larger and rougher range of environments than Lego models.
If Lego is about cleaning up and smoothing the real world enough that it behaves like a frictionless computer world, Meccano is about learning the meditative art of pursuing the truth in inconvenience of dealing with the high-friction messiness of the real world. Though it’s a toy, it can be even messier than some real-world “real work” things like assembling Ikea furniture.
Now what does all this have to do with friction, AI, meaning, and zero-interest rates?
Meccano teaches “truth in inconvenience” by exposing you to the messiness of the real world in a calibrated way, so you learn the difference between design knowledge and reality knowledge. While I can imagine playing with digital versions of Lego (aka Minecraft &co), there would be little point in a digital version of Meccano. Much of the fun and learning comes from it actually being physical.
Tolerance stacking is only one example of a phenomenon where an apparently “clean” planned process — assembling a set of modular, composable components according to a precise and bug-free plan to arrive at a goal state —runs into trouble due to a small amount of randomness creeping in at each step, and accumulating in a way that causes the governing plan to eventually run into a formally “mysterious” problem. It’s a version of the butterfly effect, but in a much less chaotic system.
In fact, that’s why these problems seem “inconvenient.” They are fundamentally harder to deal with because they’re mysterious within cleaner schemes of convenient truth, which feature nice mathematical models and lovely symmetries.
When you deal with inconvenient truths, you have to deal with their randomness and weirdness with no help from your theorizing.
If you’re lucky, the inconvenience will manifest merely as glitchy errors in your matrix [1] models. Epistemic problems.
If you’re unlucky, you’ll be faced with phenomena you don’t even have words for. Ontological problems.
I call them Ghosts Outside Machines. Artifacts of primitive randomness unfactored into the categories of your finite reality. I mean, it’s only fair. If you choose to live in imaginary worlds, the real world is going to gaslight you with things you don’t have words for.
Ghosts Outside machines
See, the thing is, plan errors and gross execution errors can be detected with reference to the plan or design itself. Internal consistency checking of the geometry — a math problem — can be done with just the design. Gross errors like off-by-1-hole can be detected by checking the evolving physical artifact against the design through discrete validation processes, a kind of syntax/grammar checking comprising, in the case of Meccano, things like counting holes. The problem is within the realm of what computer scientists call formal verification. Detecting errors in plans or in idealized execution states is something like proving theorems.
But tolerance stacking is a problem that is “outside” the scope of the abstract model being instantiated. It is about unmodeled realities seeping into platonic realms that are not aware of its existence. A version of illegibility assaulting high-modernist thought.
It is a problem that arises from the abstractions of the model “leaking,” and accumulating in a way that causes detectible effects that are “impossible” within the logic of the pure model, like a clearance in the nominal geometry turning into an interference. [2]
Of course, in the case of Meccano, you could expand the model itself to make such errors legible. For example, model all the compliances and slot clearances explicitly, and actually predict where the assembly will land in theorem-proof ways. To use this modeled information, you’ll of course need to measure the physical model itself in very precise ways, for distortions and deviations. Eyeballing, or loosely counting holes will not be enough. But the point is, no matter how good the model, there will always be a larger realm outside that’s beyond the reach of formal methods, which will always leak in, manifesting as seeping primitive randomness, like a leaking roof (as it happens, during the ongoing Los Angeles, Blizzard 2023 my ceiling seems to be leaking via the kitchen exhaust vent). This is because formal methods are by definition ontologically finite. They work within finite vocabularies.
A process like tolerance stacking is a specific instance of a more general element in ontologically finite models of reality: how randomness enters into expectations, and drives deviations from expectations articulated in terms of formal, closed-world descriptions.
How do you think about such things in general ways?
In graduate school, I took a great sequence of two courses on generalized nonlinear distributed stochastic control, a field devoted to building models with the fewest possible restrictive assumptions. If most modeling fields are about spherical cows, this is a field that makes no assumptions about cows at all. The professor (one of my favorites, Demosthenes Teneketzis at the University of Michigan) took great pains to drill a few key principles of modeling real systems into us.
At the top of the list was the importance of identifying the primitive random variables correctly over writing down clever equations. They represent the informational boundary conditions of your model. Get them wrong, and all your cleverness won’t help you.
A primitive random variable is one that affects the reality you’re interested in, whose value you don’t control, and is set by the world. It might be a reference input, a disturbance, or a noise, but the point is, you don’t control it. You can only make assumptions about it, such as assuming a statistical distribution, and try to measure it. The modeling approach we learned was built around how the primitive random variables interacted with all the other model structure you had, to create other, dependent signals. Importantly, the randomness enters the system at all times, not just at the beginning. It’s pesky chaos-driving butterflies all the way.
Primitive random variables lead naturally to the idea of the information structure of a problem, which is a model of “who knows what, when” and leads to a “dirty” approach to the problems of team coordination and game theory. One that puts back some of the messiness that generally gets taken out in prettier, less useful models.
The result of this kind of modeling is invariably highly general equations, kinda like weather models, describing noisy distributed systems, full of agents with imperfect, evolving local knowledge. These equations generally have no formal solutions. Even simulating them is generally too hard to be worth the trouble (they are almost always NP-hard). By making a lot of simplifying assumptions, you can find solutions for specific spherical cow cases, but in general, the point of the theory (and the courses) is not to help you solve unrealistic easy versions of problems, but appreciate why complex versions are so hard to solve in the general case, and why it might be better to just go try things in the real world. The point is to arrive at insights into the nature of complexity and the limits of design and theory. The results published in the field tend to be about things like fundamental limits, impossibilities, trade-offs, locally effective heuristics, and so on.
The field, and the two courses I took, were/are not very popular, even within the narrow world of control theory of which it is a subfield. They are something like Mathematical Meccano, designed to expose you to real-world difficulties and messiness. By contrast, the bulk of the larger field of control theory is devoted to more Lego-like regimes, such as LQG control (which includes ideas like “Kalman filtering” that even people outside of engineering have heard of).
Lego and LQG control are examples of toy and real engineering that operate in relatively “clean” regimes where you strive to stay away from messiness by accepting a few constraints and limits. As I will argue later, disembodied generative AI belongs in this class as well. In narrow domains, they can be surprisingly effective. Outside those domains, they tend to fail unpredictably.
Meccano and generalized stochastic control are examples of toy and real engineering in “dirty” domains, where you strive to incorporate as much messiness as possible in your thinking, while still doing useful things. You may get less done, but anything you do get done is significantly more robust. Robotics belongs in this class of engineering disciplines.
Or to repeat my title theme, Meccano, generalized stochastic control, and robotics generate more “truth in inconvenience” when you try to turn untested design knowledge into tested reality knowledge. They tell you about the limits of what you know.
Lego, LQG, and generative AI, by contrast, help you avoid inconvenient truths for as long as possible.
Constitutive Knowledge
Messiness in the sense of forced truth-in-inconvenience lessons we’ve been talking about, manifesting in phenomena such as tolerance stacking and emergent mechanical assembly show-stopper alignment problems, is a manifestation of friction in the real world.
Let’s talk about friction. Not the helpful kind that helps Lego blocks stick together and allows wheels to roll, but the messy kind that (sometimes) prevents Meccano models from coming together.
In high school or college, if you went down the STEM path, you probably encountered simple models of friction. For example, the two famous “coefficients” of static and sliding friction, and a friction curve relating input to resistance force that ramps up to a peak before falling slightly to a plateau (the up-slope, up to the peak, is “static friction,” while the plateau is sliding friction).
Maybe later you learned about more kinds of friction, such as viscous drag, which is a smooth function of velocity, and hysteresis, which is a sort of energy loss cycle marked by a forward and backward paths of a cyclical system not being the same.
These “laws” of friction are not like the elegant laws of fundamental physics, but what are called constitutive laws. Empirically determined relationships based on reality-testing data. They typically have no elegant theoretical justification, and have to be both validated for specific circumstances before being used, and grounded by determining the parameters for specific circumstances. Planck’s constant is the same for everything, but the coefficient of friction or drag has to be measured for pairs of materials with specific contact geometries. On the plus side (if you can call it that), friction tends to be a phenomenon friendly to ignorance and brute forcing. You don’t have to know the coefficient of friction or drag if you can generate enough force to simply get past it, or add enough roughness to prevent slipping.
Constitutive knowledge is sometimes contrasted with “absolute” knowledge, but some philosophers (like Nancy Cartwright iirc) argue it’s all constitutive knowledge. Even the “fundamental” laws of physics. For now, think of constitutive knowledge as knowledge that can only be generated through reality-testing, and fundamental knowledge as knowledge that can be generated from elegant models and mathematics and limited amounts of data.
From a mathematical point of view, it is useful to distinguish three regimes of friction, corresponding to three kinds of classical mathematical modeling regimes.
Nearly Conservative systems, like ideal planets orbiting a star, have no serious friction at all (so in an ideal case, they conserve energy and have constant entropy). They can be modeled by Hamiltonian equations, the nicest kind around. There are no perfectly conservative systems of course. Even in orbital mechanics, irreversible entropic change can happen due to things like tidal friction, things pulling other things apart, stars blowing up, and so on.
Nice non-conservative systems, like an airplane in the atmosphere, do have serious friction, but it is well-behaved, like smooth functions of velocity that can be elegantly incorporated into nice equations. You can use slightly more general, but messier equations, like Lagrangian models, to solve them.
Ugly non-conservative systems, like rovers on a rough path, have many sources of messy, discontinuous friction and non-linearity. You generally cannot model them holistically. You can use classical Newtonian equations to describe patches of behavior, and then compose them in pieces, with lots of “glue” in between, in the form of measured constitutive parameters.
The first two regimes are clean enough to be almost entirely automated. You can set up simulations and they’ll run accurately years to decades into the future. You can predict where Jupiter will be 10 years from now, no problem. You can model and simulate what an airframe will do in fairly complex atmospheric conditions, getting to at least statistical if not deterministic predictions.
The last regime... not so much. Even something apparently as clean as billiard balls colliding rapidly gets impossible to model or simulate beyond a very short horizon (the constitutive parameters in the picture have to do with elasticities and air drag).
The first two regimes yield highly convenient truths, in the form of elegant mathematical models that go a long way towards helping you deal with the realities pointed to by designs, and with computer-simulated worlds being very close to the real thing, regardless of what you want to do.
The third regime yields truth in inconvenience. The math models you can build are ugly and low-leverage. The simulations are janky and need a lot of tuning. The results are mostly constitutive knowledge, like knowledge about coefficients of friction and how they affect things.
Setting up simulations in the third regime is a matter of assembling a set of smaller, bespoke models together, and the result is generally nowhere near accurate or precise enough to be used for reality-checking in even a statistical sense. At most, you can get a general narrative sense of the sorts of things that can happen (not coincidentally, kinda like ChatGPT gives you a general narrative sense of the sorts of thing people say). Mathematical modeling and simulation in this regime is closer to building little games inspired by reality than “modeling” it.
Now here is the thing about friction. In some sense, friction is how reality tells you your models are wrong, in the form of earned constitutive knowledge.
And because models are always somewhat wrong, there is always non-zero friction when you try to take model-based “designed” or “planned” actions in the world. And this is not a function of your limited intelligence. Even down near absolute zero, around apparently zero-friction phenomena like superfluidity and superconductivity, effects like the uncertainty principle kick in (the reason you can’t get to actual absolute zero is because it would violate the uncertainty principle — you’d be able to know the position and velocity of a particle with zero uncertainty).
Friction exists around intentional behaviors because models are limited and operate within leaky abstraction boundaries across which primitive random variables can sneak in continuously, messing up your well-laid plans. And do so in a way that you can’t model and simulate your way out of. Your only option (where “you” is all agents involved in the situation) is to deal with the constitutive information structure, or if you like, friction knowledge, of your problem — who knows what, when that is unguessable through a priori design and simulation — as it emerges.
And perhaps most importantly, you can’t brute force your way out of these problems either. Regardless of what your model is about, or what the goals of a design are, it is wrong in some way that will produce friction if you try to act on it. That friction will embody knowledge with a constitutive information structure. And if everything is sufficiently complex, that friction that constitutive information structure will affect something you care about given enough time, even if you are indifferent to others’ interests, such as not wanting to be turned into paperclips.
Friction and Interest Rates
Here’s a fun way to think about friction — it is an interest rate on untested knowledge. The higher the friction a theory/simulation based design can expect in the real world, the higher the “interest rate.”
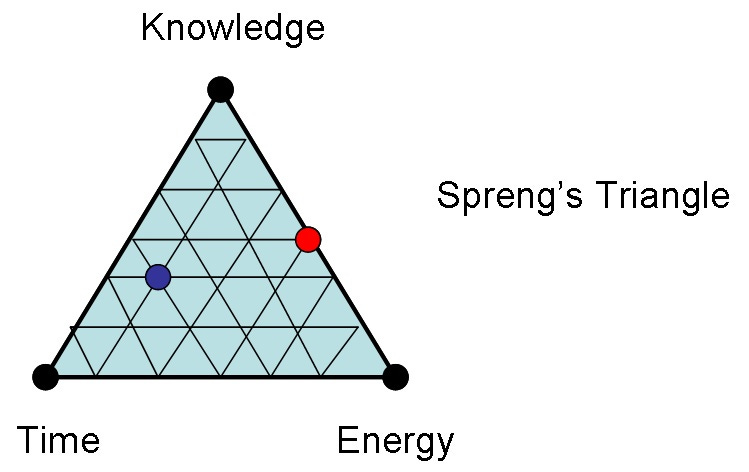
You know something, you try to use it in the real world, it doesn’t work, so you add some combination of more knowledge, brute force, or just time (trial and error) to make it work. These three form one of my favorite triangles, known as Spreng’s triangle.
Suppose I know something, in the sense of say a Meccano design, complete with instructions. I haven’t tested it out, but I’ve checked the nominal geometry and verified that it can be put together using my instructions, and using known data on time for individual operations, I estimate it will take 5 hours.
I give it to you under the condition that you pay me back in kind, with interest. What might that “interest” comprise? Well for starters, at the very least, if you try to assemble it and learn all sorts of things about tolerance stacking and cramped corners, you can tell me everything you learn.
You could give me back constitutive knowledge in exchange for my design knowledge, in three forms. In order of value added:
Tweaked plans that fix various assembly difficulties you’ve discovered, so now it’s the closest tested bit of bug-free knowledge, ie incorporating explicit constitutive knowledge.
Vague information of how you had to jiggle and force at various steps, and a subjective assessment of difficulty, including actual time it took you, maybe 7 hours. Maybe with a video of the process. This is implicit constitutive knowledge.
The finished model itself, with no further information (because you have none, because you mindlessly brute forced). I have basic proof of buildability now, so that’s something, but to get any information ROI, I’d have to analyze the build, including any warps, scratches, bends, and so forth, to figure out useful things. This is embodied constitutive knowledge.
All this is “interest on knowledge” because I saved you time by getting you as far as models and theories can, and you discovered and added constitutive knowledge.
What about the relative value of the two kinds of information though?
I might want more than this information, because maybe I spent way more time/energy/knowledge building up the initial design than you did testing it. So maybe I expect you to pay me $100 for my design, with say a discount of $15 if you agree to send me your testing report or sample build to examine (returnable).
But maybe I suck at actually building the models and sorting out the friction issues. In that case, the knowledge is more valuable to me. Maybe I give you a $25 discount, or even a free design. Or even pay you to test my design. All these regimes of planning/execution are possible, depending on the “messiness” of the domain, the complexity of the design, and the relative value of ab initio generated design knowledge and reality-testing data/constitutive knowledge.
But these valuations aside, it’s obvious that the three kinds of return have decreasing amounts of value. I’d rather have explicit and legible tested knowledge than illegible and implicit, and purely embodied is the least helpful since I have to do most of the work still. All three though, are constitutive knowledge. It isn’t elegant design or math knowledge, but knowledge that’s more like knowing a coefficient of friction.
Or you could “pay me back” with a more complex design later, with more parts and steps added, with more nominal functionality. If it took me 10 hours to design the original model, and you pay me back 5 hours later, maybe you at least have to give me a more complex model worth 5 more hours of my design time. Depending on the relative messiness of the real versus design worlds, I may prefer more complex designs as my return, over more reality data.
Why might I prefer more complex designs (more design knowledge) over reality testing data (constitutive knowledge)? Well, if we’re in a regime where everything works really well and according to plan (Lego-like regimes as opposed to Meccano-like regimes), reality data is both less valuable and takes longer to accumulate in sufficient quantities to be valuable.
But maybe designing is easy, and competition ensures that designs rapidly get more complex over time. So I need a more complex design in the future to stay competitive than the design I’m selling you right now. There is a historic cost to time because we’re in a regime where model-based information is simply compounding and commoditizing rapidly, building on itself. If the world is sufficiently non-messy relative to the rate at which ab initio complexity can be added to designs, then an exponential competition will kick in for a while. Eventually things will get complex enough that reality data starts getting more valuable faster, turning the exponential into an S-curve plateau, but until then, I’ll prefer my knowledge ROI in the form of more complex theoretical designs rather than reality data.
I’m not a finance guy, but my point is, you can think about these things using interest rates on both design knowledge, discovered through just thinking about abstractions, and on reality knowledge, discovered through trying things out and discovering the patterns of real-world friction that affect things.
In these terms, Lego is a “low-interest-rate” design toy, while Meccano is a "high-interest-rate" design toy. A Lego design is more valuable than reality-testing data because it is (by design) kept away from high-messiness regimes. You’d need a significantly more complex Lego model to generate the same amount of testing data as a simpler Meccano model. [3]
Or to put it another way, given a particular “reality testing budget,” Lego models can get more complex than Meccano models. In fact, you probably shouldn’t try to get to a significantly complex Meccano model without testing the buildability of subassemblies and partial assemblies along the way.
If you used say, an AI program to come up with generative designs for both Lego and Meccano, you could go crazier with the former. Perhaps Lego models of 100s of pieces are buildable while Meccano models of mere 10s of pieces run into real-world buildability issues.
Okay, we’re finally ready to talk about zero interest rates, AI, and meaning.
Zero Interest Regimes
In recent discussions around zero-interest rate macroeconomic regimes, a common observation has been that startups can get much bigger before their business models are significantly tested. When capital is very cheap, you can test your urban scooter business by dumping thousands of scooters in a dozen cities rather than dozens in a few neighborhoods in one city. It’s an explosion of scooters. Not exactly an intelligence explosion, but some sort of explosion.
Zero-interest rate startup business models are like Lego. When capital is cheap (and expecting corresponding lower returns), not only can you build out more aggressively, you kinda have to, because the capital wants to be deployed at much larger scales. Because billionaires are used to a certain lifestyle, and if they can’t rent out a million dollars at 10%, they would rather rent out 10 million dollars at 1% than cramp their lifestyles.
The world of startups is always full of weird ideas being contemplated and executed on at all levels from paper napkin to billion dollar prototypes. What makes regimes of cheap capital so weird and interesting is that ideas that would have gotten killed at paper-napkin or small test scale in high-interest-rate regimes are allowed to get much bigger and wilder, and die of the problems that manifest at much bigger scales, often by brute-forcing through ones that occur at smaller scales.
It’s not just 2010s private sector startups that had this characteristic. If you look back at American defense contracting in the 1950s and 60s, you’ll notice something very similar with aerospace innovation. Hundreds of the weirdest, strangest ideas for airplanes and weapons systems got to prototype and even limited-run production scales because government money was effectively cheap and unlimited. It wasn’t till the 1970s that high-interest rate economics truly kicked in.
The point about zero-interest-rate regimes is that a wilder variety of ideas can, and must, develop far further than they do in high-interest-rate regimes, in order to generate the same level of absolute return on knowledge. In doing so, such regimes delay the onset of truth-in-inconvenience regimes, when friction knowledge and tested reality data can catch up to the surfeit of untested design knowledge.
***
Let’s translate capital and interest rates back to the world of knowledge and friction. What exactly is “capital” in physics terms here? Arguably it is the equivalent of brute-force energy or time. It contains no knowledge, but can be used to generate and value knowledge. Return on capital is expected return on knowledge, in terms of future knowledge. This knowledge can either be design knowledge, or reality (constitutive) knowledge. In terms of Spreng’s triangle, you want to move from the time+energy edge, to the knowledge vertex.
Given a certain amount of capital, and a prevailing interest rate, what’s happening to knowledge levels? There are at least four possibilities, which form a 2x2 of real versus artificial, and low versus high interest rates.
Real Low-Interest World: Untested theoretical knowledge is being accumulated because reality data is low value, and theory is both cheap to produce, and translates very frictionlessly to tested reality knowledge.
Real High-Interest World: Tested knowledge is being accumulated by trying to actually use theoretical knowledge, because reality data is higher value and all theory needs a lot of testing to be of use. In addition, new theory may be very costly to produce and reality testing (trial-and-error time) is simply cheaper.
Artificial Low-Interest World: Untested theoretical knowledge is being accumulated despite the presence of a lot of expensive friction, because the reality data only matters to powerless people, via negative externalities. This is elite overproduction.
Artificial High-Interest World: Tested knowledge is being accumulated by doing a lot of reality testing for low-value constitutive knowledge even though the theory is much higher value and cheaper to produce, because of very high risk aversion.
Both the last decade, and the 1950s-60s, had elements of both 1 and 3. There were engines of exponential design knowledge production like “Uber for everything” or “any random thing that can plausibly fly” that could be cheaply designed and tested for value, and significant costs were being borne by disregarded actors suffering negative externalities. By contrast a mix of 2 and 4 is characteristic of cautious, and perhaps bureaucratically risk-averse cultures, with some mix of real and imagined fears driving the caution.
In terms of truth-in-inconvenience, 1 ignores it with no consequences, 2 seeks it out, 3 ignores it with delayed consequences, and 4 seeks it out unnecessarily.
Or in terms of our running examples, we’re talking about Lego worlds, Meccano worlds, Meccano worlds being force-fit into Lego frames, and Lego worlds being force-fit into Meccano frames.
Which of these best describes AIs entering our world?
The Debut of AI
If you’ve been following this newsletter and general technological trends, it should be somewhat obvious where I’m going with all this, but let me sketch out the main details.
Computers, of course, can digest a lot of data, and produce even more data. The digested forms, measured by compression ratios achieved, even rise to the level of “knowledge,” even if such knowledge is mostly illegible to humans. But is it design knowledge, a working out of abstract possibilities, or constitutive (or “friction”) knowledge? It certainly looks messy like reality data, doesn’t it?
LLMs and large image models digest basically the entire internet, and produce generated data from vastly larger possibility spaces, but crucially, the amount of data involved at any stage is dwarfed by the amount of reality data it points to. Generated text contains orders of magnitude fewer bits than any realities it talks about. Generated imagery has orders of magnitude fewer bits than things that exist or could exist. Even generated code has orders of magnitude fewer bits than all the computing environment contexts it might be compiled or executed in, and the logged data from bugs and crashes (digital “friction”) it can expect in production.
So despite the apparent messiness, all the knowledge and data is design knowledge and data, categorically similar to the knowledge in an untested Lego or Meccano build design, rather than knowledge about tested designs.
The equations are bigger and more complex than the geometric ones that might be used by a CAD tool to make an assembly design, but they comprise the same sort of theoretical knowledge. Yes there are various friction-like constitutive parameters in the models (with names like “temperature”) but overall, generative AI produces untested design data, not reality data. Which means it will run into the same sorts of problems human-generated design data does, when tested against reality.
So generative AIs produce design knowledge. Untested knowledge that may or may not be easy to turn into reality knowledge. If it is easy, it may or may not be valuable to turn into reality knowledge.
Generated midwit text may be good enough to replace some midwit economic roles. If basic marketing copywriting is disrupted by generative AIs, we’ll see “reality data” very soon in the form of the “friction knowledge” of click-through rates.
Generated code may be good enough to replace ordinary sorts of programming with lower-skilled minor bug-fixing work. We’ll see reality data in the form of total cost of creating and maintaining code by putting in human labor hours and GPU hours.
If generated imagery kills custom artwork rates, we’ll see the reality data in terms of the value of, say, games and movies created with generative technologies. We’re already close to being able to build capital allocation and ROI models for these things.
Which of our four interest-rate scenarios from the previous section apply to the encounter between AI and reality?
I think AI supremacists are expecting AIs to be deployed into a real, low-interest world, ie, a Lego-like world, where the constitutive-knowledge return on generative knowledge invested is relatively low value compared to simply churning out more generative knowledge. So they expect the AI models to run furiously and unchecked, mostly open-loop, driven by an exponential process of internally driven self-improvement, with the evolutionary environment for models being primarily other models and model-based simulations.
You produce an LLM and get a lot of excitement going. Your competitor spins up their own LLM and tries to produce even higher excitement. Notably, neither tries to invest much in deeper reality testing in high-friction, “high-interest” regimes, because the ROI on more design knowledge is so much higher. We’re at the exponential part of the curve where the rate of return on knowledge is purely a function of the amount of existing knowledge, because we’re only seeking design knowledge. It’s like a lot of people spending a lot of money simply making up what they hope are highly buildable Lego designs that can be deployed at very low interest rates in the world.
Curiously, it doesn’t make a difference whether we’re talking optimistic or pessimistic AI supremacists. The optimists think the runaway AIs will overwhelm all real-world friction and create a paradise. The pessimists think the runaway AIs will overwhelm all real-world friction and create a paperclip-manufacturing dystopia. Both assume that the world is Lego-like to a sufficiently powerful model, trained on sufficiently rich data streams (including, presumably, blog posts and photos of messed up Meccano-builds teaching the AIs about tolerance stacking).
I think this view is basically wrong. Because intelligence is not the main factor governing what happens to ideas when they encounter real-world friction. As knowledge mining processes shift from generating design knowledge through cheap production, to generating constitutive knowledge through expensive testing, things slow down drastically, because constitutive knowledge is simply not as compressible as design knowledge. Once you learn the equations of physics, not much intelligence is required to start compiling vast databases of friction coefficients. But those databases take time to accumulate and space to store. It’s a grind. The gap is much bigger than the one between natural language as described by grammar rules, and as it exists in human society. Intelligence won’t help you much. What will help is finding viable “return on investment” regimes where grinding is worth it.
As with humans, the hunger of capital seeking returns makes the process ripe for delusions. Whether it in the form of accumulated capital, or accumulated hyperparameters, there is a temptation to project low-interest-rate fantasies onto high-interest-rate realities. To pretend that Meccanos are Legos. This is the artificially low interest rate world.
The more thoughtful sort of AI risk pearl-clutcher generally worries about this kind of scenario. Where the cost of reality testing design theories is high, but only matters if you want to protect humans. Just as Evil Capitalist Corps go around deploying cheap capital to litter cities with scooters, while ignoring the plight of say cobalt miners [4] in Africa oppressed by the battery supply chains, the fear is that a sufficiently powerful AI will go around living in a fantasy "low-interest-rate" reality, treating the world like a set of Lego blocks, and implementing bad designs that may or may not work to fulfill the AI's goals, but are highly likely to kill humans in some way.
The problem with this scenario is that just about any complex real-world goal, whether or not it takes human welfare into account, will run into a ton of friction and be forced to learn truths-in-inconvenience through slow, grinding processes, not explosive fugues of just figuring everything out. Because again, intelligence is not the bottleneck.
Yes, it can create hazardous messes, just as unbridled capitalism can, but it isn’t going to some special sort of super-intelligent mess. It isn’t going to be immune to the booms and busts of alternating low and high-interest rate regimes, and changing relative values of design and constitutive knowledge.
I personally think AI will run into a real, high-interest world, ie a Meccano type world, where it slows down radically the moment it exits the artificially frictionless world of internet-scraped text, images, and simulation environments (this world may not seem frictionless to our social minds, but compared to reality data, it is). The result will be something like a supersonic flow expanding out of the computational substrates of the world hitting reality at a shock wave boundary and turning into a subsonic flow.
In other words, AIs will discover the regimes we embodied meatbag human intelligences have always already inhabited but don’t talk about much online for AIs to learn from: there is truth in inconvenience.
The Meaning Crisis Explained!
Finally, let me say a few words about the meaning crisis. I think there’s no more succinct formulation of it than the one made up by Drew Austin: what if your entire life turned to be a function of zero interest rates?
From our discussion so far, we can provide a very compact answer: it’s like imagining you’re building with Lego all your life, and suddenly learning you were building with Meccano, and the thing doesn’t come together properly when it finally needs to.
In fact, the fates of Millennials exiting the zero-interest-rate regime and encountering inflation for the first time as adults is a bit like a supersonic flow turning into a subsonic flow at a shock boundary. Or like startups based on littering cities with thousands of scooters discovering their business model doesn’t actually balance in a sustainable way.
Or like AIs based on reading exabytes of forum posts descending into robot bodies and discovering that the world doesn’t work quite like Very Online humans act like it does.
The meaning crisis, in my opinion, is a case of mistaking a Meccano world for a Lego world, overextending and overgrowing into it too quickly, encouraged by artificially low interest rates, and being forced to learn a lot of truth-in-inconvenience knowledge very quickly, via a knowledge shock event. The knowledge is specifically a pile of constitutive knowledge being dumped on us in short order. A bunch of highly incompressible primitive random information we’ve been ignoring in our models for far too long.
The natural response to this kind of knowledge shock is to scale back actions and ambitions to the point where design knowledge and friction knowledge of the world are in a better balance. If zero-interest realities are all you’ve known in your life, this is traumatic. A meaning crisis. Nobody told you this would stop being fun.
But as you might discover if you graduate from Legos to Meccano, and learn some patience, it actually is fun. The truth in inconvenience is the best kind of truth. After over a century of economics driving relentlessly towards more convenience, maybe it’s a good thing we’re being systematically forced to grapple with less convenience, both as humans, and via our newly minted naive AI assistants that are just beginning to understand what reality is.
Something similar to this is what you’re seeing in the “infinite chocolate bar” gag. It’s not really about the Banach-Tarski theorem as is sometimes claimed; it’s about real chocolate bars being messy real things rather than perfect geometric objects.
Here, I’m only thinking about engineering usability data, not about things like marketing appeal of a particular kit, or color schemes that are more or less popular.
The cobalt shortage appears to have been reversed though: https://www.reuters.com/markets/commodities/cobalt-price-slump-triggers-lift-off-futures-trading-2023-02-07/