Join 📚 Kevin's Highlights
A batch of the best highlights from what Kevin's read, .

Git: A Pictorial Walkthrough
Brij Kishore Pandey
In [theoretical computer science](https://en.wikipedia.org/wiki/Theoretical_computer_science),
the **CAP theorem**, also named **Brewer's theorem** after computer scientist [Eric Brewer](https://en.wikipedia.org/wiki/Eric_Brewer_(scientist)),
states that any [distributed data store](https://en.wikipedia.org/wiki/Distributed_data_store)
can provide only [two of the following three](https://en.wikipedia.org/wiki/Trilemma) guarantees:
[Consistency](https://en.wikipedia.org/wiki/Consistency_model)
Every read receives the most recent write or an error.
[Availability](https://en.wikipedia.org/wiki/Availability)
Every request receives a (non-error) response, without the guarantee that it contains the most recent write.
[Partition tolerance](https://en.wikipedia.org/wiki/Network_partitioning)
The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
CAP theorem
wikipedia.org
[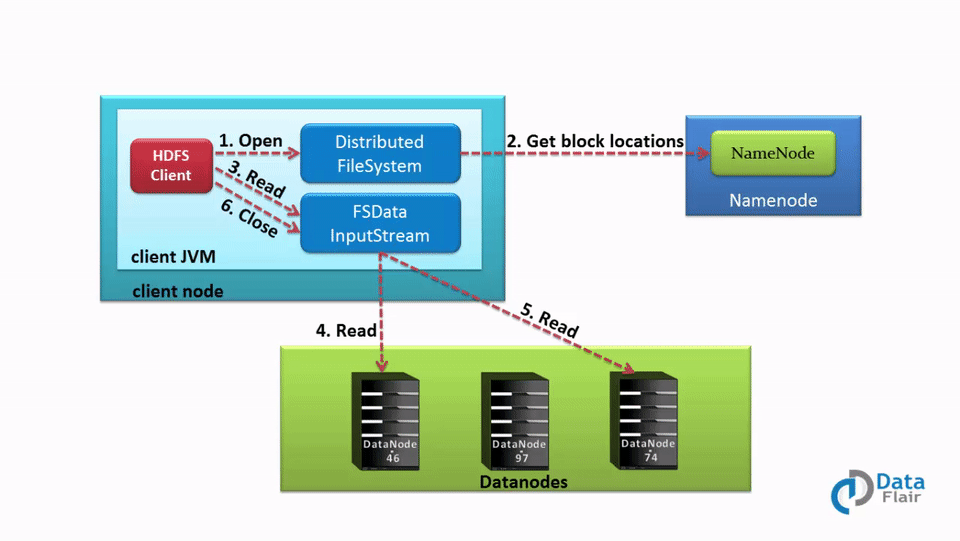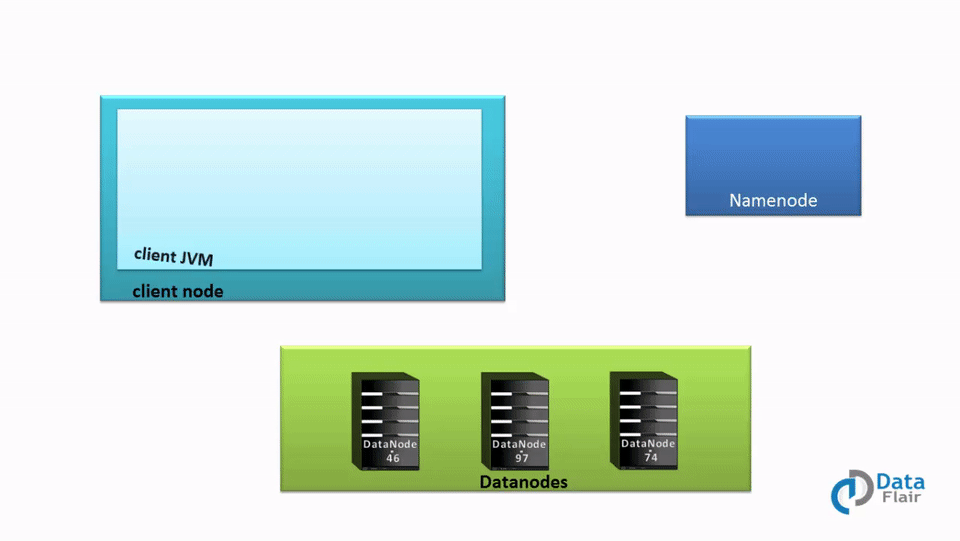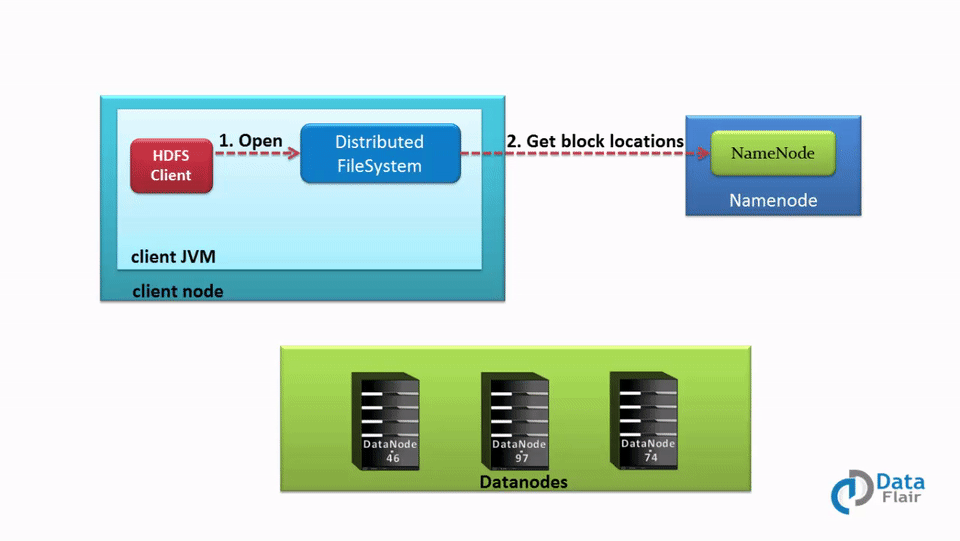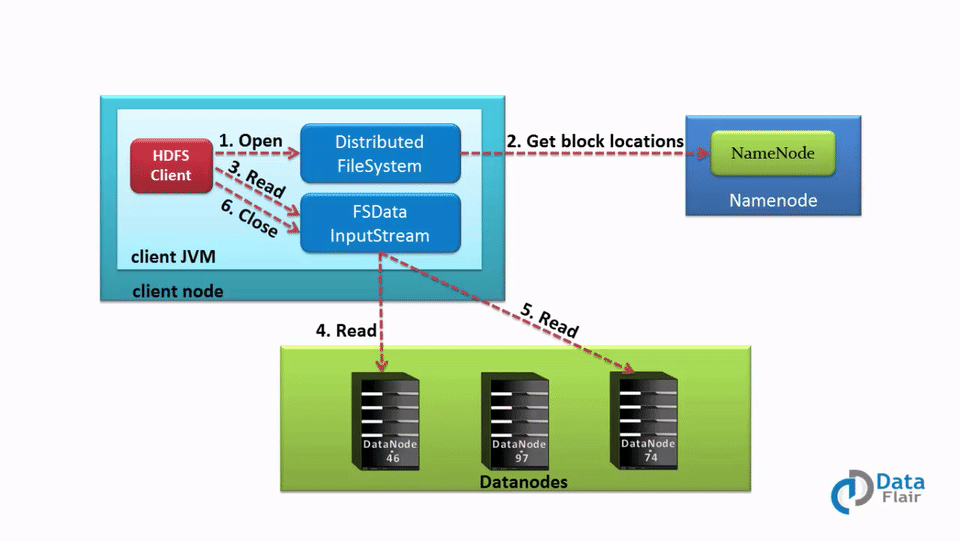](https://data-flair.training/blogs/wp-content/uploads/sites/2/2016/05/Data-Read-Mechanism-in-HDFS.gif)
Data Read Operation in HDFS – A Quick HDFS Guide
DataFlair Team
...catch up on these, and many more highlights